

本書內容主軸為設計及實作一射擊遊戲引擎,而這個引擎是由一彈幕描述腳本 (script) 語言所驅動,全書內容圍繞於此中心思想並只討論及介紹所有相關技術細節,其餘無關的技術及程式基礎內容則不在本書討論範圍之內。全書共有十個章節。第一章對捲軸射擊類型遊戲 (STG) 的演化歷史作一個介紹,對各個時期的演化作一個回顧,讓讀者對射擊遊戲的演變有個基礎的認識。
第二章的內容對射擊遊戲裡的主角:子彈 (bullet),作一個全面及深入的研究,從各種角度去分析及研究在射擊遊戲中各種不同類型的子彈的行為,並推廣至子彈所構成的各種更豐富變化的樣式:彈幕 (bullet hell)。最後從對子彈及彈幕的研究中,抽取出其中的重要特徵,並以此作為接下來設計一彈幕描述腳本語言的基本準備。
第三章的內容是對第二章中對子彈及彈幕的研究及了解後所作的一個總結,從無到有一步一步的設計出一套專門用來描述各種子彈及彈幕的腳本語言:STGE。因為對子彈及彈幕的了解設計出來的彈幕描述語言,從中所粹取出來的對於子彈的特徵,STGE 語言並不只局限於被應用來描述子彈,而是能夠被更廣範的用來描述各種類型的粒子 (particle),這點在本書最後實作射擊遊戲作總結應用時就能夠看到。
完成了彈幕描述腳本語言 STGE 的設計之後,接下來的工作就是實作一個可以用來執行 STGE 指令的虛擬機器 (virtual machine)。在實作 STGE 虛擬機器之前,第四章介紹了一個物件管理器 (object manager) 的資料結構 (data structure):Object Pool。Object Pool 是個通用的資料結構,在遊戲中被應用來作物件的有效管理,在 STGE 虛擬機器中也扮演了一個很重要的角色。第五章實作了一個可以執行 STGE 指令的虛擬機器,在實作上因為採用了可以簡單和程式結合的策略,所以我們在可以在擁有可以剖析 STGE 語言的語言剖析器 (parser) 之前,就可以先以程式碼的形式寫下可以直接編譯執行的測試腳本。這在初期的引擎開發給我們帶來很大的便利,讓我們可以每次只專注在某一個技術環結上面,層層架構出每一個階段的功能來。
完成了 STGE 虛擬機器的實作後,接下來我們就需要一個可以解析 STGE 腳本語言的解譯器,可以讀取使用文字編輯器編輯好的 STGE 腳本,轉譯成 STGE 虛擬機器可以執行的指令。第六章介紹了實作語言剖析器的相關技術及工具,作為正式實作 STGE 語言剖析器的基礎。第七章使用了在第六章裡所學習到的知識實作 STGE 腳本語言的剖析器,並且在第八章裡實作了一個簡單的測試工具程式,可以載入文字編輯器編輯好的 STGE 腳本,經過 STGE 語言剖析器解譯後,直接在 STGE 虛擬機器執行,並觀看執行結果。在這一章裡面,我們使用 Web 的技術來製作工具程式。檢視器 (viewer) 的部份使用 HTML/Javascript 實作,並使用 HTML5 的技術來作動畫展示。而因為語言剖析器 (parser) 是 C/C++ 實作的,為了可以共用程式碼,所以使的技術把 C/C++ 撰寫的語言剖析器 (parser) 以及虛擬機器執行時期 (virtual machine run-time) 編譯成 Javascript,整合進 Web 工具程式。
第九章介紹一個狀態堆疊的資料結構:Stage Stack。這個資料結構在遊戲裡可以應用來作結構化的流程控制 (program control),讓程式的邏輯規劃更清楚,在開發上更容易維護。第十章裡,整合應用了全書的所有知識及技術,實作一個小型的射擊遊戲,作為本書的總結。在這一章裡面,我們使用 STGE 語言設計只有一個關卡 (level) 的射擊遊戲,雖然只有一個關卡,但也包含了一般射擊遊戲關卡的基本元素,以 STGE 語言來描述各時間點敵機如何進場出場以及如何作攻擊。和一般射擊遊戲一樣,在關卡的終點也有一個頭目 (boss),我們一樣以 STGE 語言來創造頭目的各種移動及攻擊彈幕。此外,在本章中也能學習到 STGE 語言如何被應用在子彈及彈幕之外,如在遊戲中用來製作爆炸效果、選單動畫、背景星空等等。
飛行射擊遊戲 (Shoot 'em up,縮寫 STG) 是射擊類電子遊戲的子類型。在飛行射擊遊戲中,玩家角色(多駕駛飛船或飛艇)隻身突擊,在躲避敵方攻擊的同時射殺大量敵人。飛行射擊的設計元素組成沒有一致觀點。狹義的飛行射擊要採用太空飛行器或特定類型的角色移動;廣義則允許角色步行及多種視角。飛行射擊遊戲考驗玩家的反應,並需要玩家記憶關卡和敵人攻擊方式。彈幕射擊遊戲則採用密度很高的炮彈。
此類遊戲起源可追溯到最早的電腦遊戲之一的《Spacewar!》,這款遊戲於1961年開發,最終1970年代在電子遊樂場發行。但一般觀點是將《太空侵略者》創造者西角友宏視為類型發明人。《太空侵略者》1978年首次在日本大型電玩推出。飛行射擊在1980年代和1990年代早期流行。飛行射擊在1990年代中期成為小眾類型,遊戲遵照1980年代確立的慣例設計,且越來越迎合專門狂熱者,尤其是在日本。
太空戰爭!(Spacewar!):1962年由 Steve Russell 和同學們在 MIT 開發的電腦遊戲,被認為是第一款電腦遊戲之一,也是第一款射擊遊戲。
太空侵略者 (Space Invaders):1978年由日本 TAITO 公司開發的射擊遊戲,成為了當時的文化現象,對後來的射擊遊戲產生了深遠的影響。
宇宙巡航艦 (Gradius):1985年由日本 KONAMI 公司開發的射擊遊戲,是橫向卷軸射擊遊戲的代表作之一,引入了充能攻擊和選擇性武器等元素,成為了後來射擊遊戲的模板之一。
R-Type:1987年由日本 IREM 公司開發的射擊遊戲,將遊戲難度提高到了新的高度,引入了武器升級系統、強力的 boss 戰等元素,獲得了廣泛的讚譽。
雷電 (Raiden) 是日本 Seibu 開發在1990年推出的縱向捲軸射擊遊戲,台灣當時的代理公司是亮華電子。後來已經作為一種象徵,代表了一種類型的遊戲。
Radiant Silvergun:1998年由日本 TREASURE 公司開發的射擊遊戲,將連鎖攻擊、武器升級和特殊攻擊等元素結合在一起,成為了射擊遊戲的另一個經典代表作之一。
斑鳩 (Ikaruga):2001年由日本 TREASURE 公司開發的射擊遊戲,引入了黑白兩種能量屬性的概念,成為了縱向卷軸射擊遊戲的經典代表作之一,被認為是射擊遊戲的巔峰之作之一。
Stardust Vanguards:2015年由美國 ZANNEFT 開發的射擊遊戲,結合了動作、策略和多人遊戲的元素,讓多人同屏互動的射擊遊戲成為了現實,並且在 indie 遊戲界中得到了廣泛的認可。
Blue Revolver:2016年由日本 STUDIO SISTERS 開發的射擊遊戲,引入了多種攻擊和防禦機制,並且具備高品質的畫面和音效,成為了當代 2D 射擊遊戲的代表之一。
在這一章裡面,我們會對子彈以至於子彈所構成的彈幕作一個分析及研究,目的是想要從中抽離出一般化的基本元素,透過這些基本元素我們也就能夠設計出一套專門用於描述子彈及彈幕的腳本語言 (script)。本章由對子彈的研究開始,逐漸的將研究範例擴大到彈幕。研究的目的在於從各式各樣不同種類的子彈以及彈幕裡,去找到其中的基本構成元素,這些基本元素是和圖形畫面無關的特徵屬性。找到這些基本構成屬性之後,就能夠定義及描述單一子彈的移動,再以此為基礎推廣到多數子彈的定義及描述子彈群的運動以構成彈幕。這些知識將在下一章裡,被應用來設計出一套通用的,專門用來描述子彈及彈幕的腳本語言:STGE (ShooTing Game Engine)。
彈幕研究的對象是彈幕幾何圖形,而這些彈幕幾何圖形是由運動中的子彈群所構成的,因此研究彈幕就是對子彈作研究。子彈是構成彈幕的最小基本單位,如只是從外觀來考察的話,在射擊遊戲裡可以找到許多不同類型的子彈,如能源彈、針彈、炸彈、飛彈、追蹤彈、雷射、子母彈等等。
| 能源彈 | 這是在射擊遊戲裡面最尋常最多見的子彈類型,配合不同顏色和大小的能源彈能排列成簡單但華麗多樣的彈幕。 |
| 針彈 | 這是帶有方向的子彈。在畫面上,我們可以看到針彈會指向它的前進方向,這樣就可以得知子彈的前進方向。針彈和能源彈一樣,也是構成彈幕的主要基本元素子彈類型。 |
| 炸彈 | 炸彈的特殊之處在於,當它受到攻擊或者是在一定時間經過後會爆炸。而在爆炸的同時可能會炸出能損害自機的碎片,或者是又再炸出其它子彈,也就是說這是一種會生成子彈的子彈。 |
| 飛彈 | 飛彈常常是射擊遊戲裡面令人感到棘手的對象,因為飛彈常比一般子彈飛的更快且具有追蹤能力,發射出來後就不停的追著自機跑。還好有些追蹤飛彈不會是永遠追著自機,而是只追蹤自機一段時間後再朝最後的方向飛逸。 |
| 雷射光束 | 雷射光束一般只會作直線前進,偶爾會結合追蹤自機的能力,或者還會彎曲而不只是呈現直線光束。通常雷射光束的移動速度會比普通的子彈還要快速非常多,如果沒有事先預測避開雷射光束,通常很容易瞬間就被擊斃。 |
上表所列為幾種比較具有代表性的子彈,除此之外當然還有其它更多種類的子彈。只是大多是上述子彈的變型或比較少見所以就不特別列出。另外若只從外觀來看子彈的話,在畫面上的子彈還分成會動的與不會動的,不過這可不是在說子彈有沒有位移,而是指子彈畫面上的呈現有沒有使用動畫 (animation)。一般子彈只使用一張靜態圖,有時會使用幾張圖切換作出子彈在旋轉等動態效果,或者像飛彈具有尾焰或煙霧,讓遊戲畫面更豐富華麗。
在開始對子彈的運動模式 (movement) 作觀察之前,請想像一下當畫面上的彈幕全部暫停凍結的時候,忽略掉畫面上不同種類的子彈的不同外觀,則剩下來的就是構成彈幕的每一個子彈的位置。也就是每一個子彈的最基礎的屬性,就是它在畫面上的座標位置 (location)。而在實際進行遊戲的過程中,畫面上的所有子彈並不是靜止不動的,而是不停的在運動,也就是畫面上的所有的子彈的座標位置都在不停的改變。
造成畫面上的子彈的座標位置的改變的原因,則是接下來我們要指出的二個關於射擊遊戲裡面的子彈的重要屬性 (property),即子彈的移動方向 (direction) 以及移動速度 (speed)。我們在畫面上看到的華麗的彈幕雖然複雜,一一拆解下來也只不過是一個一個的各別子彈的運動。經由運動,畫面上的子彈不斷的改變自己的座標位置,並和畫面上的其它子彈之間的相對位置共同構成彈幕幾何圖形。有了這二個屬性,就能夠定義出畫面上所有子彈的運動,所以我們需要先對這二個重要的子彈屬性有所了解。
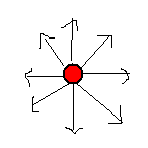 | 方向 | 因為我們研究的是在二維平面上的射擊遊戲,所以對於子彈的方向來說可能的值是0到360度之間,以一個角度就能夠定義出子彈的移動方向。在子彈的移動過程中,如果改變方向角的話,子彈會立刻朝不同方向移動。 |
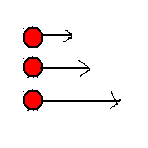 | 速度 | 有了速度子彈才能運動,否則就會在原地靜止不動。我們將速度定義為在1秒鐘的時間之內的單位移動量。單位移動量愈大則移動速度愈大,若移動量是負數的話則表示朝反方向移動,不過為了統一起見,對於反方向移動的指定我們會以改變移動方向來作指定,而不使用負的移動速度方式來實現。 |
雖然子彈的外觀種類有許許多多,有不同顏色的、有大小不同的、有實心也有空心的子彈、有定速的也有變速的子彈等等,可說是應有盡有多采多姿。但說穿了,其實我們大可把這些花樣繁多的外觀給拋棄,全部都一視同仁的把這些子彈當作是一個方塊或圓圈圈,或一個一個的質點或粒子。如上一小節所說明的,因為這些都不是真正的重點,重點是在於這些子彈是怎麼樣運動的。
雖然子彈的運動是由很簡單的移動方向和移動速度所定義,但根據子彈和畫面上其它子彈或自機等環境物件之間的交互變化,可以歸納出一些可以明顯觀察得到的運動模式來。
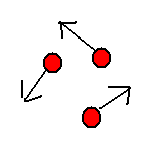 | 方向彈 | 這是射擊遊戲裡面絕大部份的子彈使用的移動模式。從子彈被發射產生出來的那一瞬間,子彈就被指定了一個固定的移動方向和速度,接著這枚子彈就會一直朝著那個方向作等速直線運動往前飛,直到移動超出顯示畫面外或者擊中目標被消滅為止。 |
 | 追蹤彈 | 在介紹子彈外觀時,我們提到了追蹤飛彈會一直追著自機跑。為了達到追蹤的目的,也就是說子彈在移動的過程中必須不斷的改變行進的方向,把目前的前進方向改變為指向自機的方向,這樣一來就能產生追蹤的效果。調整改變行進方向的時間差,就相當於調整追蹤的精細度。 |
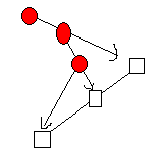
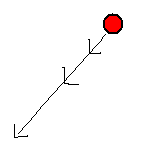
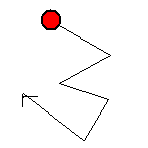
 | 瞄準彈 | 瞄準彈是介於方向彈和追蹤彈之間的子彈類型。瞄準彈在剛產生出來的時候就和追蹤彈一樣,立刻就想追著自機跑,所以它的前進方向就設為指向自機的方向。等到開始移動後就又變成了方向彈,朝著一開始設定好的方向直線前進而不再改變行進方向。 所以如圖中所示,在子彈發射當時方向指向當時自機的方向,也就是瞄準自機發射。接著自機移動開來閃躲子彈,但子彈的前進方向仍然固定不變,朝初始移動方向繼續前進。 |
 | 變速彈 | 一般的子彈都是等速度移動的,而變速彈會作加速度或減速度的運動,忽快或忽慢,讓你更難掌握住子彈移動的時間差來作迴避。 |
 | 變向彈 | 和追蹤彈一樣變向彈也會改變方向,差別只在於追蹤彈改變的方向永遠都指向自機方向,而變向彈改變的方向則可能朝向任何角度。 |
除了以上幾種主要的子彈運動類型之外,還有其它特殊運動模式的子彈類型,例如像是會忽隱忽現或忽大忽小的子彈、會瞬間移動的子彈、碰到場景邊綠會反彈的子彈等等,但大體都是上述幾種子彈類型的變化。
一群子彈經由上述的子彈移動模式組合,共同構成彈幕幾何樣式 (pattern)。底下介紹幾種最基本及常見的彈幕樣式,所有更複雜的彈幕樣式都可以由以下基本樣式變化得到。
 | 環 | 從發射點開始也就是圓心位置,同時朝四面八方射擊子彈,而這些子彈是固定的間隔角度排列時,就能構成環形的結構。子彈數目愈多,而子彈之間的間隔角度愈小,所構成的環就愈接近一個平滑的圓。 |
 | 扇形 | 這是環型樣式的變化。射擊的時候和環形樣式一樣,以同樣間隔角度連續射擊,差別只在於發射的子彈數量還不足以構成一個環形,只能夠構成環形的一部份,也就是一個扇形。扇形的方向可以是指定一個固定方向,或隨意方向,或是指向自己方向。 |
 | N-Way | 這也是扇型樣式的變化。射擊的時候連續以等間隔時間朝同樣的方向發射出扇形子彈,就能構成 N-Way 樣式的彈幕。同扇形一樣,N-WAY 的方向可以是指定一個固定方向,或隨意方向,或是指向自己方向。 |
 | 旋渦 | 嚴格說起來,旋渦形的彈幕樣式也是屬於環形樣式的一種變化型式。主要的差別就在於,環形樣式在發射子彈時是同時發射所有子彈,而旋渦樣式則是會以等時間間隔的方式一個一個發射子彈。 |
 | 亂數 | 幾乎所有的遊戲都需要使用亂數,沒有亂數的話遊戲就會變的很無趣。在這裡亂數的作用是用來發射出散亂的子彈,作出好像是天女散花的效果。以亂數隨機指定的屬性,可以區分為隨機的射擊方向及隨機的移動速度。 |
 | 分裂 | 分裂彈也是常見的一種變化,這種類型的子彈當分裂時不只單單分裂成一或二顆子彈,常常還可以配合上述的幾種樣示,分裂出更多變化的子彈來。比如說,一個子彈爆炸後分裂為一個扇形或環形彈幕。 |
在前面我們看過彈幕的基本樣式、子彈的移動模式和屬性。那麼彈幕是如何產生的呢?根據觀察,發射子彈的方法裡面有幾個主要的因素會影響到發射出來的子彈,使這些發射出來的子彈因為發射時的某些條件不同而產生出能夠形成彈幕的變化。這幾個變數分別是:射擊時間差、子彈速度的變化、射擊角度間隔和亂數。
射擊時間差射擊時間差是產生彈幕最基本的變數。想像一下,假如我們朝某一個方向射擊十次,每次射擊出來的子彈的速度都一樣,但是這十次射擊的中間沒有任何停頓,那麼在畫面上看到的結果就好像只發射了一發子彈,因為這十發子彈全部重疊在一塊了。
反過來說,假如這十次的射擊動作,每次都會作一個短暫時間的停頓,即使因為這十次射擊都是朝相同的角度射擊出相同速度的子彈,但因為每一發子彈之間存在了一個時間差,結果就可以造成在畫面上的子彈也會有個等距離間隔,因而構成形成彈幕的基本要素。

如上圖所作的測試。左邊朝右下角方向射擊十次同樣速度的子彈,但中間沒有任何時間差,所以結果就和只射擊一次子彈看起來沒什麼兩樣。而右邊的測試在射擊時加上了一個時間差,其餘參數相同,以上二個結果立即可以比較出二邊的差異來。
子彈速度的變化子彈速度的變化在實際應用上可以區分為靜態和動態二種不同類型。
所謂靜態指的是在射擊時使用不同的子彈初速度,以這種方式射擊出來的子彈,假如是朝向同樣的方向,過一段時間之後就可以觀察到速度快的子彈追上速度慢的子彈。而動態的子彈速度變化,並不侷限於射擊時子彈初速度及之後的移動速度是否是保持在常數,重點在於射擊出來的子彈,在飛行過程中子彈速度會產生變化。
射擊角度從前面介紹的彈幕基本樣式裡可以看到有幾種不同的形狀,有些形狀和方向沒有任何關係,比如說圓形或旋渦是無法分辨它的朝向;而有些樣式和方向有直接的關係,例如 N-Way 或扇形樣式。射擊的時候因為射擊角度的不同,結果在畫面上造成了不同的彈幕圖案。在射擊的同時,除了角度的變化之外,假如再加上時間差的變化,就能夠產生出更多變化的彈幕。
在下圖中可以看到,左側的彈幕是由扇形所構成,而右側是由環所構成。這二組彈幕都是由二個不同波次的射擊構成,第一波次朝幾個等間隔角度的方向射擊一個基本形狀的射幕,接著延遲一小段時間,然後在下一波次的射擊,再作一次朝幾個等間隔角度的方向射擊一個基本形狀的射幕,不過角度有作了一點偏移。一直重複同樣的動作,構成了如圖中所示的彈幕,這是結合時間差的變化樣式。

扇形的彈幕很明顯,可以很容易一眼就看出它的彈幕形狀和方向的關係。而環形雖然沒辨法在靜態的圖片中很容易看出它的形狀和方向的關係,但因為射擊時角度不同,造成整個形狀的前進方向不同,動態的結果就能夠在畫面上造成明顯不同的圖案。
亂數亂數常使用在各種工程問題的模擬上來協助產生更接近真實世界情況的資料,在遊戲中更是不可少的一項重要功能。要是沒有了亂數,現在我們就沒有幾個遊戲可以玩了。稍微想像一下一個沒有亂數的遊戲會怎麼樣,例如 Windows 中的連環新接龍 (Spider) 假如沒有亂數的話,不管你玩了多少局,每一牌局的內容都是一模一樣,那肯定會很無趣不用多久就會厭煩。
在彈幕射擊遊戲中的亂數直接應用彈幕產生上的比例和其它情況會相對較少,因為亂數產生出來的彈幕就只有一個字可以形容,那就是亂。如果子彈全都以亂數方式產生,則畫面上一團亂全無規律模式可言,這樣就不能稱之為彈幕了。至於如何應用,則要視彈幕的設計者而定。通常亂數的使用是以受控制的亂數的形式來應用,例如射擊的子彈的速度是在一個指定範圍而不以完全隨機方式指定,這是為了達到預想的目的的前題來應用亂數。
射擊遊戲中的敵機以搭載武器的方式將彈幕發射器 (emitter) 掛載在機身上面,隨著敵機的移動,在畫面上呈現出來的彈幕也跟著產生了變化。
實際上,假如我們把子彈的概念抽象化的話,把子彈視為粒子,甚至也不要有什麼載體的概念,所有載體也一視同仁,都當作是粒子。加上這一層抽象化之後,整個事情就變的單純且更加靈活有彈性了。假如所有東西都是粒子,那就是說可以發射粒子的粒子在作用上就和原來的載體定義是相同的,但把所有東西就視為粒子,卻可以讓我們在處理上簡化許多。將所有東西粒子化的這個概念,在下一章所要設計的用來描述粒子的腳本語言是最重要的中心思想。
有了粒子這個抽象化但又明確的定義之後,我們就不需要特別再去研究載體怎麼移動,它的行為模式是如何,現在我們只需要研究粒子就足夠了。至於真正的粒子要如何定義,是子彈、飛機或碎片等,就留待給應用自行去定義,對於彈幕引擎來說,它只知道一種粒子。
在上一節裡我們提到的四個影響彈幕產生的變數:射擊時間差、子彈速度的變化、射擊角度間隔和亂數。現在我們要再加上最後一個變數:移動的發射器。上節中,當我們在作分析時,還沒有考慮到發射器本身的行為,事實上我們是作了一個發射器是一個點並且是靜止不動的假設,而運動中的發射器是會影響到彈幕的形狀的另一個重要變數。

在上圖中,左右二側的彈幕都是以相同的演算法產生。唯一的差別只在於左側的發射點是靜止不動的,而右側的發射點會左右來回作小幅移動。可以明顯的由上圖中觀察到,僅僅只有發射點的運動有些許的不同,就能造成最終形成的彈幕形狀有所不同。不只如此,當多個發射器同時相互作用時,產生出來的彈幕圖形更會是千變萬化。
在上一章中,根據對子彈和彈幕的分析及研究,從中抽離出子彈及彈幕的基本元素。有了這些認識後,在本章中我們將應用對於子彈的認識及知識,從無至有一步一步的建立出一套專門用來描述子彈及彈幕的腳本語言 (script language):STGE。STGE 是 STG (Shooting Game) Engine 的簡寫,也就是射擊遊戲引擎語言的意思。我們從如何定義及發射一枚子彈開始,再以此為基礎不斷的改善及擴充語言的能力,最終的結果讓我們可以用 STGE 語言來描述出各種複雜華麗的彈幕。
雖然 STGE 語言是以描述子彈及彈幕為出發點而設計的,但是因為對於底層引擎來說,實際上它所針對的對象是和外觀沒有任何關係的物件,也就是更一般化的粒子 (particle),所以把 STGE 語言視為一粒子描述語言 (particle script) 會比把它當作是子彈描述語言會更加合適。這點在本書的最後一章總結實作一射擊遊戲時,可以看到更具體的應用。在最後一章裡,你將可以看到 STGE 語言,不只被應用於描述子彈及彈幕,它還能夠用來描述關卡、敵機、選單、爆炸效果等等。
在開始前,先定義基本的 STGE 腳本語言基本構造。和一般的程式語言比較起來,STGE 語言是簡化許多的程式語言 (programming language)。屬於一領域特定語言 (domain-specific language),是專門針對特定應用領域的計算機語言。因為在功能上來說可算是定制的,因此複雜度也比不上一個真正的程式語言,但是相對於一個真正的程式語言來說,還是有許多可以供借鏡的地方。考慮到靈活性,所以需要提供類似高階語言的函式呼叫功能,這樣子才能夠把複雜的程序分解成小程序以便於在不同的地方呼叫,同時也對於程式的維護上有所幫助。因此現在可以定義下第一個 STGE 的語法。
script name end
以上是 script 區塊的語法,這裡把一個函式或程序叫作一個 script 區塊。一個 script 是由 script 和 end 關鍵字的程式區塊所構成,接在 script 後面的是函式的名稱。如果你懂得一些高階程式語言的話,script 的概念應該可以很容易了解和接受,因為在這裡 script 的概念就同在程式語言內的副程序 (sub-routine)。一個 STGE 語言腳本是由零個以上的 script 區塊所組成,每一個 script 區塊都能夠單獨或配合呼叫其它 script 區塊執行。
每一個 script 區塊都需要給予一個獨一無二的名稱。和許多程式語言一樣,name 名稱我們只能夠使用規定的字元來命名,包含大小寫的英文字母、數字以及底線符號。另外 name 的第一個字元規定不能是數字,只能是大小寫的英文字母或者是底線符號。和許多程式語言一樣,name 的大小寫是有所區別的,也就是說 abc 和 Abc 或 ABC 是三個完全不一樣的名稱,這點需要特別注意。
為了統一起見,STGE 語言中的所有關鍵字一律全部使用小寫英文字母。此外也不能使用 STGE 語言內建的關鍵字 (如 script 或 end 等)作為的 script 區塊的名稱。
所有的程式語言都必需支援註解 (comment) 的語法,除非寫出來的程式碼本身很簡短且能清楚明白的說明自己的動作意圖,否則程式碼一旦變大變複雜之後將會變的難以理解也無法繼續維護。STGE 語言也支援程式註解,目前只有支援單行的註解,所有在分號之後的字元一直到行尾為止的所有字元全都被當成是註解看待,這點類似 x86 組合語言 (assembly language) 的程式註解。有了註解的語法之後,我們就可以在程式裡面加註說明,這樣一來在往後自己或是由其它人繼續作程式維護時,也能夠根據註解裡的訊息快速的掌握原來的設計思維。
; 這是註解,分號之後全都是註解 script abc ; 這也是註解,分號之後全都是註解 end
接著可以開始定義指令了,首先要定義一個可以用來發射粒子的指令,每次執行一道發射粒子的指令,就會產生一個粒子。
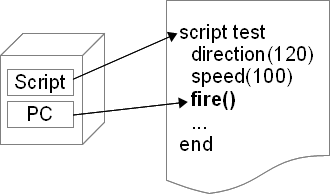
script test fire() ; fire 指令可以發射一枚粒子 end
在這個簡單的例子裡面我們看到了一個新定義的指令,指令名稱叫作 fire。首先注意到 fire 指令後面有一對小括號。參考一般程式語言的語法在函式名稱後面加上一對小括號,這樣在程序裡面對於一個名稱是不是代表一個指令的呼叫就能一目了然,整個呼叫看起來也會一致。同時繼續發展下去就會發現到,指令呼叫也需要提供能夠傳遞參數功能,有了傳遞參數的功能之後才能作出更靈活變化的彈幕,而指令的參數也會借鏡一般程式語言的方法,把參數列放在括號之間,各別參數以逗號分開,至於詳細說明在後面會再提到。
根據以上對 fire 指令的定義,每次呼叫一次 fire 指令就會發射一枚粒子,所以如果想要一口氣發射五枚粒子的話,那麼就需要連續呼叫五次 fire 指令,如下所示範。
script test fire() ; 發射第一枚粒子 fire() ; 發射第二枚粒子 fire() ; 發射第三枚粒子 fire() ; 發射第四枚粒子 fire() ; 發射第五枚粒子 end
STGE語言並沒有像是一些程式語言一樣規定在語句的最後要加上分號表示一條程式語句 (statement) 的結束,也就是說,不管換行或空白把全部的指令都擠在一塊也無所謂,如下所示範。
script test fire() fire() fire() fire() fire() end ; 全部擠在一起的寫法
以上是把上一個一次發射五枚粒子的範例重新編排過的版本,功能完全一樣。雖然從功能面來說,對電腦而言是相同的,但對人類來講就變得不容易閱讀了。畢盡撰寫程式的是我們,因此為了方便自己閱讀,建議該加上空白的時候就加上空白,該換行的時候就換行,必要的時候也可以加上適當的縮排 (indent) 以增加程式的可讀性。
到此為止你應該會發現到一個問題,那就是剛剛發射的粒子會往那裡跑?要回答這個問題,接下來需要定義關於粒子的二個重要屬性:方向及速度。
移動方向及移動速度是粒子的二個最重要的屬性,一枚粒子的運動是由方向及速度二個屬性來定義的。那麼方向及速度又是如何作定義的呢?
在 STGE 裡,方向是由角度所定義的,使用0到360度的區間來定義粒子的移動方向,如果想要用負角或是超過360度的角也沒有問題,只不過內部在作運算的時候會自動調整到0到360之間的角度。角度以畫面正右方也就是 X 軸的正方向為0度,順時針方向旋轉為正方向。
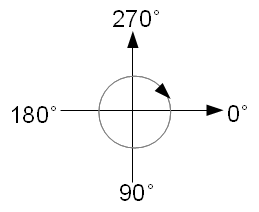
至於移動速度則是以單位時間的移動量來作定義。單位時間所指的是秒,而移動量是由在電腦銀幕上的像素 (pixel) 來作定義。因此如果移動速度是100的話,方向是0的話,相當於每秒鐘粒子會朝正右方移動100個像素。
script test direction(90) ; 移動方向90度 (正下方) speed(100) ; 移動速度100像素/每秒 fire() end
上面的範例發射一枚粒子,在粒子發射之前使用了 direction 和 speed 指令分別定義了粒子的移動方向為90度和移動速度為100單位。執行到 fire 指令時,新產生的粒子即會套用當前的移動方向及速度設定,立即朝正下方以每秒100個像素的速度移動。
script test direction(0) ; 移動方向0度 (正右方) speed(100) ; 移動速度100像素/每秒 fire() direction(180) ; 移動方向180度 (正左方),移動方向繼續套用原設定 (100) fire() end
上面這個範例總共發射了二枚粒子。第一枚粒子往右方0度方向射出,第二枚向左方180度方向射出,速度都是100單位。注意到第二次的 fire 指令前只有設定方向而沒有指定速度,那是因為每次指定的方向或速度都會一直保留著,因此上次一指定的速度100就會繼續被下面 fire 指令套用而不必要再設定一次。也就是說,假如在第二個的 fire 指令是連接在第一個 fire 指令之後沒有使用 direction 和 speed 指令作方向及速度的設定的話,那麼第二個 fire 指令所發射出來的粒子的方向及速度就會和第一個 fire 指令所發射出來的粒子一樣,也就是方向0度 (正右方)及速度100單位。
補充說明一點,假如一開始沒有設定粒子的移動方向和速度的話,那麼預設的方向及速度都會是0。也就是說預設的方向是正右方,而因為預設的速度是0,所以粒子是靜止不動的,這點需要特別注意。要是發現呼叫了 fire 指令但粒子卻靜止不動時,就要先檢查是否忘記了設定移動速度。或者當發現 fire 指令發射的粒子只會往右邊跑,那就要檢查看看是否忘記設定移動方向。
在上一節的範例裡看到在同一時間之內發射了二枚粒子,當然也可以應用同樣的手法在同時間內發射更多的粒子,也就是多加幾條 fire 指令。但如果這麼作的話,因為 script 會一口氣從頭執行到尾,所有的 fire 指令都會在同一時間內一起被執行,也就是所有粒子都會在同時間發射出去。假如我們想要作到每隔一秒再發射一枚粒子的話,使用這樣的手法就辨不到,因此需要提供一個新的指令來支援這個功能。為了達到這個目的,我們設計了 sleep 指令。
sleep 指令需要一個時間參數,這個時間參數是用來告訴指令說我們想讓程序暫停多久之後再繼續執行,時間的單位是秒。這個功能就如同 Windows API 裡面的 Sleep 一樣,呼叫 Sleep 並指定一個時間之後,呼叫 API 的程序就會進入休眠直到等待的時間到了為止才會醒來繼續執行工作。有了 sleep 指令就有辨法作到間隔一段時間後再發射粒子的功能了。
script test speed(100) fire() sleep(1) ; 暫停1秒 fire() sleep(2) ; 暫停2秒 fire() end
在上面的例子裡面總共發射了三枚粒子,不過現在就不再是同時間發射。發射了第一枚粒子後經過了一秒鐘之後才再發射第二枚粒子,在第二枚粒子發射之後經過了二秒後才又再發射第三枚粒子。三枚粒子中間都會間隔一小段距離,因為一開始的速度是設定為100,而發射的時間間隔都是1秒,所以加上時間差,第一第二枚粒子的間隔距離會是100個像素,而第二第三枚粒子的間隔距離會是200個像素。
在上一個範例中一共發射了三枚粒子。在這個範例裡面因為只有發射三枚粒子,所以還算不了什麼,還可以手工一個一個以 fire 指令產生出來。但假如現在需要發射一百枚粒子的話,再以同樣的方法一個一個以 fire 指令產生粒子的話就不是個好方法了。
為了減輕撰寫一大堆指令的負擔,我們需要迴圈的功能,而這也是電腦之所以有用的一個非常重要的功能。和 script 區塊一樣,迴圈也定義為一個程式區塊,把它設計成是一個程式區塊的好處是可以在區塊裡放進不只一條指令,在應用上會更加有彈性。同時在迴圈區塊之內因為可以放進任何指令,而迴圈本身也是指令區塊,所以迴圈之內還能再放入迴圈區塊,作出巢狀迴圈的應用。綜合以上的需求和想法,設計出 repeat 指令。迴圈區塊是由 repeat 及 end 關鍵字所構成,而接在 repeat 關鍵字後面有一對括號,括號中的數字則是用來指定迴圈的執行次數。
script test
speed(100)
repeat(5) ; 迴圈區塊開始,指定迴圈次數5次
fire()
sleep(1)
end ; 迴圈區塊結束
end
這個範例和前面的範例作的事情幾乎是一樣的,也是間隔一小段時間就發射一枚粒子。不一樣的地方是這裡使用迴圈來作這件事情。在迴圈區塊內,發射一枚粒子後立刻讓程序暫停一秒鐘,同樣的事情要作5次只需要設定好迴圈的執行次數即可,程式也變的簡單許多。同時只要簡單修改一下迴圈次數就可以改變發射粒子的數量。
script test
speed(100)
repeat(-1) ; -1表示無窮迴圈
fire()
sleep(1)
end
end
這個範例和上一個範例幾乎一模一樣,不一樣的地方只有迴圈次數不同,這裡的迴圈次數使用的是-1。-1是個特殊的數字,表示它會讓這個迴圈無止盡的執行下去,也就是所謂的無窮迴圈的意思。有時候我們會需要產生出沒有數量限制的粒子或子彈,這時就可以運用一個迴圈並把執行次數設定為-1,就可以達到射擊出無限數量的粒子或子彈的目的。
雖然目前已經設計了迴圈的指令,可以利用迴圈同時或間隔 (加上 sleep 指令) 的射擊出粒子。但因為目前只能指定固定常數值的方向及速度,所以想要作出環形或扇形之類的彈幕的話目前是沒有辨法達到,以目前的機制想要達成這個目的,也只能回過頭來使用最原始的方法,使用一個一個把指令寫下來的笨方法。為了要能夠作出環形或扇形的彈幕,除了迴圈的支援之外,還需要配合指定間隔的方向或速度。換句話說,也就是需要一個提供可以指定累加值的功能。有累加功能後再搭配迴圈的功能,就可以簡單的造出基本型態的彈幕了,如環狀或扇形彈幕。為了提供累加功能,需要對 direction 和 speed 指令作進一步的功能擴充。
script test
speed(100)
repeat(10)
direction(36, add) ; 每次累加36度
fire()
end
end
上面的例子,開始時設定好移動速度為100,接著設定迴圈跑10次,在迴圈裡的動作是每次發射一枚粒子,中間沒有間隔時間,而在發射粒子之前會再設定一次方向。和前面的範例不同的是使用 direction 指令設定方向時多了一個參數 add。加上這個參數後 direction 指令的行為就會變成我們前面說的累加模式,也就是每次呼叫一次 direction 指令,方向的設定就會以目前的內部的設定值再累加上指定的數值。
換句話說,假如原來設定的方向值是100,再以 direction(10,add) 的方式呼叫 direction 指令後,原來100的值會累加10,也就是變成110。因此上面這個範例執行的結果會產生一個環形的彈幕,其中總共有10個粒子組成這個環,而每個粒子間隔36度。附帶說明,在這個範例裡在開始時並沒有設定初始方向,所以會從預設的0度開始作累加。
speed 指令和 direction 指令一樣,也增加了第二個參數 add。因此也可以應用累加功能射擊出不同速度的粒子。因為道理是一樣的,就不另外再使用範例作說明。
目前已能夠使用 fire 指令發射粒子,假如可以在發射出來的粒子上面再連結一個 script 程序,讓這個程序來控制這枚粒子的話,應該會變更加有趣也可以有更多樣的變化。想像一下以下的情況,發射了一枚粒子之後再綁定 (bind) 另一個 script 給它,而這個 script 又會發射另一枚粒子,這就作成了一個簡單的子母彈應用!只要加上這點變化,就能造出更多變化的彈幕來。
為了達到這個功能,需要對 fire 指令作功能擴充。我們知道每一個 script 都需要有一個名稱,所以我們可以以這個名稱當作 fire 指令的參數,表示說在發射粒子的同時把這個 script 指定給它作綁定。如果沒有指定 script 名稱的話,發射出來的粒子的行為就和原來的定義相同。
script test direction(0) speed(100) fire(test2) ; 發射粒子的同時綁定 test2 到新粒子上 end script test2 sleep(1) direction(180) speed(100) fire() end
這個範例會先發射一枚粒子,而這枚粒子被產生出來的同時也被指定連結到 test2 這個程序,所以在這枚粒子的生命週期 (life cycle) 裡面都會受到 test2 這個程序的控制。test2 程序一開始會先暫停1秒鐘,之後再發射一枚新的粒子出來,而這枚粒子沒有連結任何程序。因此在畫面上看到的結果將會是,這枚粒子會先在畫面上往0度的方向 (正右方) 開始移動,1秒鐘之後這枚粒子會朝180度的方向 (正左方) 射擊出另一枚粒子,並繼續朝0度方向移動。
在上一節裡面我們擴充了 fire 指令的功能,讓新產生出來的粒子可以連結一個程序,讓這枚粒子變成一個會動的發射器。但因為受限於目前的 direction 及 speed 指令,在綁定給粒子的程序上呼叫的 direction 及 speed 指令就沒有辨法指定相對於粒子本身的方向及速度屬性,只能給定一個常數值,這樣一來就沒辨法從這個會動的發射器射擊出相對於發射器自身方向或速度的粒子。因此現在要次再對 direction 及 speed 指令作一次功能的擴充動作,修正後在程序內就能夠使用到綁定粒子的方向及速度屬性作參考值。
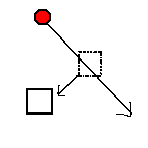
script test direction(90) speed(100) fire(test2) ; 發射粒子的同時綁定 test2 到新粒子上 end script test2 sleep(1) speed(100) direction(30, obj) ; 把方向設定為相對於粒子方向30度 fire() direction(-30, obj) ; 把方向設定為相對於粒子方向-30度 fire() end
這個範例裡面一共發射了三枚粒子。第一枚粒子發射時綁定 test2 這個程序,在 test2 程序的控制之下,一秒鐘之後 test2 程序再同時發射出另外二枚粒子。而這二枚由 test2 程序所發射的粒子分別以相對於第一枚粒子原來的角度 (90度) 的左右方向各30度的方向發射出去,也就是由120度及60度的方向發射出去。假如沒有使用 obj 參數來設定方向為相對於參考粒子的話,結果就會變成和指定一個絕對值,也就是30度角和負30度角,就和原來沒有使用這個擴充功能之前一樣。
在射擊遊戲裡由玩家所操控的主機我們稱它為自機 (plane),至於其它電腦所控制的飛機都把它稱作是敵機 (enemy)。遊戲裡面有些敵機會朝著自機發射子彈,這個功能必須要特別提供,因為在遊戲的進行中,自機和敵機都不停的在移動,因此它們之間的相對位置或相對角度也不停的在改變,我們根本沒辨法事先知道當時敵機在自機的那個方向,敵機也不能事先知道自機在那個方向,無論使用指定絕對數值或相對數值的方式都無法作到描準。因此需要提供一個能在執行時期計算瞄準自機角度的功能,為了提供這樣的功能,需要對 direction 指令再作一次功能的擴充。
script test direction(5, aim) ; 將方向設定為瞄準自機且偏移5度的方向 speed(100) fire() end
這個範例很簡單,它只發射一枚粒子。特別的地方只有在設定方向的 direction 指令我們新增了 aim 參數的用法。如果第二個參數使用 aim 參數的話,將會變成設定的方向為瞄準自機方向,假如第一個參數有指定數值的話,還會再加上這個數值當作偏移量。
到此為止,direction 及 speed 指令就完成了設計,以下表格列出 direction 及 speed 指令的定義及用法。
| direction指令 | 說明 | 範例 |
|---|---|---|
| direction(dir) | 指定方向為常數 (dir),dir 為0~360度。 | direction(120) |
| direction(dir, aim) | 指定方向為瞄準自機再加上常數 (dir)。 | direction(0, aim) |
| direction(dir, add) | 指定方向為目前方向再累加上常數 (dir)。 | direction(15, add) |
| direction(dir, obj) | 指定方向為目前連結粒子方向再加上常數 (dir)。 | direction(-30, obj) |
| speed指令 | 說明 | 範例 |
|---|---|---|
| speed(spd) | 指定速度為常數 (spd),spd 為每秒移動單位數。 | speed(100) |
| speed(spd, add) | 指定速度為目前速度再累加上常數 (spd)。 | speed(5, add) |
| speed(spd, obj) | 指定速度為目前連結粒子速度再加上常數 (spd)。 | speed(100, obj) |
接下來我們要談談算式的使用,有了算式後就可以使用在指令的參數上取代原本只能是常數的參數。STGE 語言使用的算式只能使用簡單的加減乘除運算,和一般算式一樣也能包含括號。數字及計算結果為浮點數,以下都是合法的算式。
1+(-2) 1+2*(3-4/5) (1.2 * ((3.2 + 1) / 2.5)) * 3 (9 - 8 * 7 - 5.1234) * (1 + 2 * 3)
如上面的例子所示,數字和符號之間可以不包含空白也可以插入空白,有沒有空白字元和空白字元的數量並不會影響到運算結果。
如果在程序裡面使用像上面例子那樣的算式,那就和常數值沒有什麼兩樣,應用上就不會有太大變化,所以還需要提供亂數的功能。這裡提供了可以產生亂數的函數加到算式裡面,使用亂數函數後每次計算出來的結果都不會一樣,這樣子就可以製作出更多變化的彈幕。
亂數函數叫作 rand,只能使用在算式裡面。rand 函數最多可以使用二個參數,共有三種用法。
| 格式 | 說明 |
|---|---|
| rand() | 沒有加任何參數時,rand 會回傳介於0和1之間的亂數。 |
| rand(n) | 只有一個參數時,rand 會傳回介於0和 n 之間的亂數。 |
| rand(n1, n2) | 填入二個參數時,rand 會回傳介於 n1 和 n2 之間的亂數。 |
亂數函數的參數也可以是一個算式,就好比迴圈裡面還可以再包含迴圈一樣,混合使用後就可以寫出更加變化複雜的算式。
-25 + rand() * 50 1 + 10 * rand(rand(10), 10 + rand(12, 30))
現在我們可以開始把算式放到前面我們設計出來的指令裡面取代原先的常數了,有了算式之後就可以寫出更多變化的彈幕來。
script test
repeat(-1)
direction(rand(360)) ; 在指令中使用算式
speed(rand(100, 120)) ; 在指令中使用算式
fire()
sleep(0.1)
end
end
這個範例會以間隔0.1秒向四面八方 (角度介於360之間) 隨機發射出移動速度是隨機介於100和120之間的粒子,這樣子就簡單的造出了可以射擊滿天花雨的彈幕了。
加入算式的支援之後,現在對程序作進一步的功能擴充。首先複習一下 fire 指令,經過上一次的功能擴充後,fire 指令可以在呼叫時指定一個程序名稱綁定到新產生的粒子上,但如果只是單單像這樣子只作程序呼叫的話還不夠靈活,必須要像平常寫的程序一樣還要可以傳遞參數,這樣子的程序才會有彈性。所以接下來要再對 fire 指令作功能的擴充,讓它在呼叫時可以傳遞額外的參數。
script test
speed(100)
direction(0)
fire(test2, 8, 45) ; 呼叫 test2 程序同時傳遞參數8及45
direction(180)
fire(test2, 18, 20) ; 呼叫 test2 程序同時傳遞參數18及20
end
script test2
sleep(1)
speed(100)
repeat($1) ; 在算式中使用參數1
direction($2, add) ; 在算式中使用參數2
fire()
end
end
這個範例比較複雜一點。首先執行 test 程序後會同時往左和往右各發射一枚粒子,這二枚粒子都綁定了 test2 程序來作後續的控制。二個 fire 指令都各傳遞了二個參數,即跟在第一個參數 test2 程序名稱之後的二個用逗號分隔的數字。第一組是8及45,第二組是18及20。要了解這二組參數的代表意思需要檢視一下 test2 程序的內容。
首先 test2 程序會先暫停1秒鐘之後,接著使用迴圈同時發射數枚固定間隔角度的粒子。在這裡的算式裡面看到了二個新的符號 $1 及 $2。$1 及 $2 代表的就是從呼叫端所傳遞過來的參數。也就是對應在 test 中的 fire 指令中的 (8,45) 及 (18,20) 這二組參數數值。
所以把 $1 替換成第一組參數中的8,$2 替換成第一組參數中的45後,test2 程序的內容就變的更明白了。對於第一次的呼叫表示要同時以間隔45度角發射8枚粒子。同理,第二次的呼叫則以間隔20度角同時發射18枚粒子。
剛才提到 $1 和 $2 符號是算式的一部份,也就是說它們可以再結合其它運算和 rand 等組成更複雜的算式,如下所示。
0.2 + 0.2 * $1 20 * $2 + rand(10, 12 + $1)
除了 $1 和 $2 之外,還有 $3、$4、$5、$6 總共六個變數可以使用,換句話說 fire 指令最多可以傳遞6個參數。程序可以傳遞參數之後,現在可以寫出更加複雜多變化的彈幕了!
這節來談談粒子的生命週期 (life cycle)。有時候彈幕是由幾個階段構成,例如在上面的例子裡,先發射一枚粒子,接著再由這枚粒子作為控制點再發射出其它粒子來。
script test direction(110) speed(100) fire(test2) end script test2 sleep(1) speed(100) direction(45) fire() end
在這個範例裡面,一開始朝角度110的方向發射一枚粒子,一秒鐘後再朝角度45的方向再發射一枚粒子。不過其實這個範例真正想要達到的效果是,在畫面上表現出第一枚粒子在一秒鐘之後轉向朝45度角的方向前進,所以第一枚粒子應該要讓它立刻消失以第二枚粒子取代才是。為了達到這個目的增加了 clear 指令。當執行到 clear 指令時,如果這個程序是和某個粒子綁定在一起的話,則這枚粒子會立刻被清除。所以現在可以把剛才的範例改寫成如下。
script test direction(110) speed(100) fire(test2) end script test2 sleep(1) speed(100) direction(45) fire() clear() ; 任務完成自我清除 end
最後要提醒一點,clear 指令不只會清除和控制程序綁定的粒子,連控制程序本身都會被立即被中止執行,這是需要注意的。換個角度來說,任何時候你想要中止控制程序時就可以利用 clear 指令。
指定好移動方向和移動速度,粒子就會自動的朝指定的方向以固定的移動速度動起來。在大部份的情況下,這樣的功能就可以滿足我們的需求,但有些時候我們還是會需要可以改變速度來增加變化,這樣子在應用上會更靈活多變。因此這裡又再設計了二條新指令,可以分別應用在移動方向及移動速度的變化上面。首先來看個範例,底下再作解釋。
script test direction(0) speed(100) fire(test2) end script test2 changespeed(1, 0) ; 在1秒鐘內以漸變的方式將速度變化為0 sleep(1) clear() end
在上面範例裡,一開始發射了一枚粒子,初始速度設為100,然後再以 test2 程序控制它的行為。在 test2 程序內,首先以 changespeed 指令以1秒鐘的時間令它的速度以漸變的方式變化到0,之後再清除這枚粒子。因為內部會以慢慢變化的方式把屬性從現在的數值慢慢的變為指定的數值,所以如果想要直接變化為想要的指定數值的話,只需要把變化時間設為0就可以了。現在在來看看另外一個範例。
script test direction(0) speed(100) fire(test2) end script test2 changedirection(1,-90,obj) ; 在1秒鐘內以漸變的方式將方向變化為相對-90度的方向 sleep(1) clear() end
這個範例示範了移動方向的變化。注意到在 changedirection 指令使用了第三個參數,這第三個參數的意義在 changedirection 和 changespeed 指令中是和表格 3.1和表格 3.2中定義的 direction 及 speed 指令裡面的參數是一模一樣的。
這節裡,要加上可以改變位置的指令。能夠直接改變位置的指令的話,在某些特定的應用方面會變的更容易。比如說當產生了一枚當作是敵機的粒子,而這架敵機要很會移動,一下子出現在畫面上方,一下子又從下方冒出來,又過一下子突然消失從畫面左側往右側呼嘯而過。光是以上面所設計的指令就很難作到這些移動。反過來看,假如有可以改變位置的指令,要作到這樣的功能就簡單的多了。
script test direction(0) speed(100) fire(test2) end script test2 sleep(1) changex(0, -40, obj) ; 立即將水平座標位置改變為相對於目前值的-40位置 sleep(1) changey(1, 50) ; 以漸變的方式在1秒鐘內把垂直座標位置改變為絕對值50 sleep(1) end
這個範例發射一枚以 test2 程序控制的粒子,而這枚粒子在1秒鐘後會把目前的水平座標位置改變成相對於原來水平座標位置位移-40的地方,因為變化時間是0,所以它是瞬間立即變化的。又過了1秒鐘之後,會以漸變的方式把目前的垂直座標位置改變到垂直座標為50的地方。類似於 changedirection 和 changespeed 指令,changex 和 changey 指令也可以指定第三個參數,第三個參數所代表的意義也和 changedirection 和 changespeed 指令一樣。
在前面我們已看過子程序的呼叫,也就是在執行 fire 指令時另外再指定一個程序名稱,這樣就可以在產生新粒子的同時,以另一個子程序來控制這枚粒子。有時候我們只是單純要執行一個子程序,而不想同時又發射一枚粒子,因此再增加二條新指令來作到這件事。
這二個指令分別是 call 及 fork 指令。這二個指令所可以接受的參數和 fire 指令完全一模一樣,差別只在於 call 及 fork 指令不會在呼叫的同時發射粒子。至於 call 及 fork 指令二者有什麼不同呢?要回答這個問題,先看個的底下範例再來說明 call 及 fork 指令有什麼不同會更容易了解。
script test
call(test2) ; 呼叫子程序 test2
call(test2) ; 呼叫子程序 test2
end
script test2
direction(rand(360))
speed(100)
repeat(5)
direction(20, add)
fire()
sleep(0.1)
end
end
在 test 程序內使用 call 指令呼叫了二次 test2 程序。呼叫 call 指令時,程序的控制權會立刻轉移至被呼叫的程序中,在這個例子裡是 test2 程序。而 test2 程序的動作是,隨機朝某個方向發射一個以5枚粒子組成的小扇形彈幕。整個 test 程序執行下來總共會看到二個小扇形發射出來,因為在 test 程序內使用 call 指令呼叫了二次 test2 程序。
現在重點來了,關鍵的地方就在於這二個扇形是以什麼樣的次序產生的。在這個例子中,這二個扇形會以一個接一個的方式產生,原因是使用了 call 指令。現在再把 call 指令替換成使用 fork 指令然後再執行一次,則會發生這二個扇形就會變成同時間一起產生。
call 指令就和我們平常作程式設計時寫的函式或程序一樣,當你在程式的任何地方呼叫這些函式時,只是把程式執行的控制權轉移到被呼叫的函式而已。當函式執行完畢之後,程式的控制權就又會返回到原程式的呼叫點的下一行指令繼續執行。這就是為什麼在上面這個例子裡的二個扇形是一個接一個產生出來的原因了。
而 fork 指令就相當於在呼叫的當時產生另一個動作程序來執行被呼叫的程序,呼叫者和被呼叫者都是同時在執行,沒有誰等待誰的問題。所以我們把這個例子裡面的 call 指令以 fork 指令代換掉的時候,執行結果才會變為二個扇形是同一時間產生出來的,因為使用 fork 指令會讓所有的程序不會有停頓的同時執行。了解 call 指令及 fork 指令的區別後,就能視情況應用在彈幕產生上面。
有時我們會需要條件分支的功能來達到某些目的,所以在 STGE 語言內也設計了一個指令來支援簡單的條件分支。這個指令叫作 option。option 指令帶一個參數,和 repeat 指令一樣需以一個 end 作為區塊結束。option 指令的參數表示接下來要執行 option 指令和 end 關鍵字之間的第幾條指令,以這種方式來實現簡單的條件分支。
script test
option(rand(2)) ; 用亂數 (0或1)決定分支
call(test2) ; 0的情況
call(test3) ; 1的情況
end
end
script test2
speed(100)
repeat(10)
direction(36, add)
fire()
end
end
script test3
speed(100)
repeat(8)
direction(45, add)
fire()
sleep(0.1)
end
end
上面的例子以亂數0或1來選擇接下來要作的事,如果選擇了0則執行 test2 程序,如果選擇了1則呼叫 test3 程序。如果選擇的值是超出有效指令範圍的話,則什麼事都不會發生。例如在這個例子裡,如果選擇值不是0或1的話則什麼事都不會發生。因為只有0和1是有效的選擇值,所以同時也意謂著選擇是從0開始計算,0代表第一條指令,1代表第二條指令,依此類推。
那麼如果想要作到選擇值是0執行 test2,選擇值是1時執行 test3,而出現其它的值的時候執行 test4,要怎麼作到呢?如下是一個簡單又直接的方法,也就是枚舉的方式把所有可能的值都列出來。
script test
option(rand(5)) ; 用亂數 (0,1,2,3或4)決定分支
call(test2) ; 0的情況
call(test3) ; 1的情況
call(test4) ; 2的情況
call(test4) ; 3的情況
call(test4) ; 4的情況
end
end
如以上的範例,總共只有5種可能的選擇值,用枚舉的方法沒什麼大問題。但是假如可能的選擇值有20種或更多的話,使用這個方法雖然笨但也許還是勉強可以作到。但如果是100種或更多種可能的值的話,以致於使用枚舉變的不可行的時候怎麼辨呢?這時候就得要用 else 這個一勞永逸的方法了。如以下的範例,除了選擇值是0時執行 test2,選擇值是1時執行 test3,而其它所有選擇值都歸類到 else 的情況去,全部一律都執行 test4。
script test
option(rand(1000)) ; 用亂數 (0至999之間的數)決定分支
call(test2) ; 0的情況
call(test3) ; 1的情況
else
call(test4) ; 0或1以外的情況
end
end
這一節的內容主要是針對算式作一次補完。在算式裡面除了可以使用函數 rand,變數 $1 至 $6 外。另外也還可以使用函數 sin 及 cos 還有變數 $rep、$dir、$speed、$x、$y、$w 及 $h。
函數 sin 及 cos 需要一個參數,參數值是介於0到360之間的角度,當然這個參數也可以是一個算式,可以用來計算三角函數值。變數 $rep 只能使用在 repeat 迴圈之內,可以透過這個變數得知目前是第幾次執行迴圈。如果迴圈跑了5次,則變數 $rep 的變化值則依序是0,1,2,3,4,而目前的值為4,程序裡面可以利用這個變數作相關應用。$x 及 $y 變數則很容易理解,代表目前粒子的水平及垂直位置座標值,而 $dir 及 $speed 則代表粒子當前的移動方向及速度值。
script test
speed(100)
repeat(3)
fork(test2, 1+$rep) ; 把目前的迴圈迭代值作為參數傳入
sleep(1)
end
end
script test2
repeat($1) ; 使用參數1,也就是上層程序的迴圈迭代值
direction(30, add)
fire()
end
end
以下為算式中可使用的變數及函數列表。
| 變數及函數 | 說明 |
|---|---|
| $1 | 呼叫程序時指定的第一個參數。 |
| $2 | 呼叫程序時指定的第二個參數。 |
| $3 | 呼叫程序時指定的第三個參數。 |
| $4 | 呼叫程序時指定的第四個參數。 |
| $5 | 呼叫程序時指定的第五個參數。 |
| $6 | 呼叫程序時指定的第六個參數。 |
| $rep | 目前迴圈的執行次數,計數值由0起算。 |
| $x | 粒子目前的水平座標值。 |
| $y | 粒子目前的垂直座標值。 |
| $dir | 粒子目前的移動方向值。 |
| $speed | 粒子目前的移動速度值。 |
| $w | 視窗寬度。 |
| $h | 視窗高度。 |
| rand() | 沒有加任何參數時,rand 會回傳介於0和1之間的亂數。 |
| rand(n) | 只有一個參數時,rand 會傳回介於0和 n 之間的亂數。 |
| rand(n1, n2) | 填入二個參數時,rand 會回傳介於 n1 和 n2 之間的亂數。 |
| sin(a) | sin 函數。 |
| cos(a) | cos 函數。 |
這是和應用程式比較有關係的資料設定。每一枚發射出來的粒子都會關聯幾個可以讓使用者自訂的參數,這些使用者自訂參數可以使用 userdata 指令在任意時候作改變。因為參數是由使用者自訂的,所以這些參數所代表的實際意義也是由使用者自訂,比如說它可以表示粒子的顏色、大小或生命值等等。
script test
speed(100)
direction(rand(360))
repeat(10)
userdata(rand(5)) ; 應用程式以參數1作為子彈顏色 (0..4)
fire()
sleep(0.5)
end
end
這個範例發射十枚粒子,每一枚粒子在發射之前都先以 userdata 指令以亂數設定了一個參數,亂數的值是介於0至4之間。而在這個例子裡,應用程式只使用到一個參數並且把它定義為子彈的顏色,有效值是0至4之間分別代表5種不同顏色的子彈。
userdata 最多可以指定四個自訂參數,每一個參數都可以以一個算式指定。userdata 指令所設定的參數值只有對應用程式才有意義,這點在最後一章,實作射擊遊戲時我們可以看到如何應用。
在遊戲中有各式各樣的物件 (object),我們需要使用某種資料結構 (data structure) 來管理這些物件,針對不同類型的物件或不同需求,管理物件的資料結構也會有所不同。在一個射擊遊戲裡面,子彈是數量最多的物件,如何提供一個有效率的方法來管理這些子彈,將會是一個重要的課題。假如我們所使用的子彈物件管理器 (manager) 對於物件的存取效率不夠好的話,也就意謂著我們所能控制的子彈數量就必須減少才行,否則就會因為整體遊戲效能不足而讓遊戲無法順暢的進行。假如能夠應用的子彈數量因為受到效能限制而減少,同時也意謂著我們可能就無法創造出更多華麗變化的彈幕。
在本章裡我們介紹一個物件管理容器 (container):Object Pool (物件池)。Object Pool 同時具有串列結構 (linked list) 及陣列結構 (array) 的優點,可以有效的利用記憶體空間及作有效率的物件存取操作,把它應用來作子彈物件的管理,對於 STGE 虛擬機器 (virtual machine) 的效能有十分顯著的提升,也因此可以同時支援更多數量的子彈,讓我們可以實作出更華麗富變化的彈幕。雖然 Object Pool 在本書中主要是被應用於 STGE 虛擬機器作為子彈物件的管理器,但因為這是被設計成一個一般化 (generic) 的資料結構,所以也能夠被應用於遊戲中任何當作一般的物件管理容器。
以射擊遊戲為例,子彈通常是數量最多的物件,但總數有多少目前還無法確定,所以就產生了第一個問題,管理這些子彈的容器的容量應該是固定大小 (fixed)?或者是能夠在執行時期自動改變大小 (dynamic resize) 以因應變動的需求量?這個問題在不同類型的應用裡會得到不同的答案。以射擊遊戲來說,在遊戲過程之中常常會有大量的子彈存在,在同一時間裡面畫面上可能同時會有數百個子彈在運動。在同一時間點裡,會有子彈被產生出來,也會有子彈被消滅。雖然沒辨法確定確切的數量,但至少可以抓到一個大概,這個數量最多可以假定是數千。
以最多數千個物件的數量來看,使用事先配置 (pre-allocate) 好大小固定的容器來管理這些物件會是不錯的選擇。因為事先配置好的容器裡的每個物件,在執行過程中可以一直不斷的被重複使用,其中的好處就是我們可以把重新配置及釋放記憶體所需要的時間節省下來,因為記憶體的配置及釋放的動作是相對來說比較花時間的操作。假如原來配置釋放的動作是非常頻繁的話,那最終結省下來的時間也是很可觀的,說不定還可以增加幾個 FPS (frame per second)。
在遊戲過程中畫面上可能在同一時間內會有數百個子彈在運動。實際的一個可能情況是,在同一秒鐘內會有一半的子彈產生出來,而另一半的子彈被消滅,也就是物件的配置和釋放動作是會非常頻繁的,所以效率也是需要考量的一大要點。
對於塞滿畫面上的子彈,每次在遊戲主更新迴圈 (main loop) 內都必須要一個一個對它們作各別更新,這樣才能保證在畫面上看到子彈的合理運動,以及包含其它的運算如碰撞檢查等。所以對於容器內物件的訪問 (iterate) 動作的效率也要考慮進去。
本章剩餘的內容,將設計及實作一個滿足以上三個條件的物件管理容器。這個物件管理器在本書中雖然主要是應用來作為子彈物件的管理器,但因為它被設計成一般用途的物件管理器,所以也能夠被使用於管理其它不同種類的物件。
陣列是最簡單也最容易使用的的資料結構。使用陣列有幾個好處,首先在存取上非常簡單便利,只需要知道想要存取的物件在陣列裡的索引值 (index) 就能夠立即對它作存取。另一個好處是在對陣列作巡訪動作時也是很直覺方便,只需要跑個迴圈從陣列頭到陣列尾一一對每一個元素 (element) 作巡訪,就能夠訪問到整個陣列裡的每個元素。
為了能夠在使用上很直覺便利,我們可以把物件管理容器的存取介面設計的和陣列的存取操作一樣,底下是一個簡單的範例。
ObjectPool pool; // 宣告物件容器 Object &o = pool[10]; // 取得容器中第10個物件 o.foo(); pool[2].bar(); // 直接使用容器中第2個物件
把物件容器當作是一個陣列來使用除了上述的好處之外,還可以得到一個額外的好處。因為存取陣列元素需要一個陣列索引值,對於這個索引值來說它不單單只是個陣列索引值,在其它的情況之下這個索引值也能被借用來作為一個 ID。
把陣列的索引值當作ID來看待的好處在射擊遊戲裡面可能還比較不容易感受到。舉例說明,假設目前在開發的是線上遊戲 (mmorpg),在伺服器端 (server) 我們使用自己設計的物件容器來管理物件。基於安全性的考量,從伺服器傳送到客戶端 (client) 的代表物件的資訊通常只會是個 ID,客戶端的所有操作全都只能針對 ID。
因為使用了基於陣列設計的容器,每一個物件本身已擁有一個 ID (也就是它本身在陣列中的索引值),這就免費的獲得一個額外的好處。不只如此,因為容器內的物件可以被不斷的重複使用。換句話說,在客戶端所看到的同一個 ID 的物件,在不同時間裡實際上可能代表的是不同的物件。而這件事只有伺服器知道,戶客端是無法辨別,因此無形中又提高了伺服器端的安全性。
雖然上面的例子是以連線遊戲作為範例,和我們的單機射擊遊戲沒有什麼直接的關係。但因為我們設計的容器本來就沒有針對任何特定用途,所以它才能被廣泛的應用到不同的類型程式裡,只需要我們在設計的時候稍微再多花一點心思就能獲得額外的許多好處。
按照前面的計劃我們將物件容器視為陣列,擁有和陣列一樣的存取方法,能夠以陣列索引值直接對容器作物件存取。但是問題是這個陣列索引值該如何獲得?我們需要有一個方法能夠對容器作配置動作,取得一個可用的物件,也就是獲得一個可用物件的索引值。
在前面所列出的第一條需求中,容器是大小固定事先配置好的。在一開始配置好固定大小的容器中的每一個物件都是被視為未被使用 (free) 的物件,所以配置的方法也就是相當於從物件陣列中找出一個未被使用的物件的方法。
實作這個功能的最簡單且直接的方法,就是給陣列中每一個物件設定一個是否使用中 (used) 的標記,容器初始化時將所有物件標記為未被使用狀態。當要配置一個物件時,則從陣列第一個物件開始,一個一個檢查其標記是否為可用 (free),若是則返回這個物件的索引值,同時再把這個物件的標記設定為使用中,這樣下次就不會被當作未使用的物件造成重複配置的錯誤。
這個方法很簡單,可是效率上就不太能夠符合我們的需求,因此需要設計另外的方法才行。這和設計實作細節有關,等到後面提到設計時再回頭來研究,目前只需要思考如何使用就行了。下面就寫段小程式來看看如何使用物件容器。
ObjectPool pool; // 宣告物件容器 int id = pool.alloc(); // 配置一個可用物件 (取得一個可用的物件索引) Object &o = pool[id]; // 取得容器中的物件 o.foo(); pool[id].bar(); // 直接使用容器中的物件
在範例中,我們使用物件容器的 alloc 方法來對容器配置一個可用的物件,這個方法會回傳一個可用物件在陣列中的索引值。有了這個索引值後,就可以存取及操作物件了。
到此為止還有個問題需要解決,是關於錯誤的處理。假如配置失敗了該怎麼辨?容器的大小是固定的話,一定會有配置失敗的情況發生,也就是容器中所有的物件都已被配置使用,無法再配置出一個可用的物件來,因此需要將這件事考慮進來。
因為目前是把 alloc 函數的傳回值當作是配置成功後回傳的可用物件索引值,如果想要再另外加上額外可以告訴我們失敗的訊息的話,最簡單的方法就是定義一個特殊的回傳值,用來告訴我們這次的配置動作失敗。這裡我們選擇了-1這個數字,因為陣列索引一般是定義為大於等於零的數值,所以選擇了一個容易記的數字-1來作為配置失敗的回傳值。
ObjectPool pool; // 宣告物件容器
int id = pool.alloc(); // 配置一個可用物件
if (-1 == id) {
// 配置失敗...
} else {
// 配置成功...
}
以上完成了配置功能的定義及介面設計。
和物件的配置操作比較來說,物件的釋放操作就相對的簡單。要釋放物件時,只需要把在配置時所獲得的物件索引值拿來告訴物件容器說,我們不再需要這個物件了請釋放它讓其它人可以再重新配置使用它。
ObjectPool pool; // 宣告物件容器
int id = pool.alloc(); // 配置一個可用的物件
if (-1 != id) {
// 使用物件...
pool.free(id); // 釋放不再使用的物件
} else {
// 配置失敗...
}
和配置物件的操作一樣,釋放物件的操作也有可能會失敗,因為傳遞給物件容器的物件索引值可能是不存在或是未使用中,這二種情況都會造成錯誤發生。
要處理這類錯誤,可以簡單的讓 free 返回一個值,釋放成功就回傳 true,失敗則回傳 false。或者我們也可以不作回傳,若是有錯發生時,內部就給一個 assert 或 exception,把檢查錯誤的工作交給應用程式來作。這部份屬於實作細節,等到實作時再考慮即可,目前只需要記住有這件事就行了。
這個功能可以讓使用者快速的檢驗一個指定物件目前是否正被使用中,如下所示。
ObjectPool pool; // 宣告物件容器
// 其它操作
if (pool.isUsed(id)) { // 檢查索引為 id 的物件是否正被使用中
// 物件 id 正被使用中
} else {
// 物件 id 未被使用
}
雖然在存取物件的時候,物件管理器用起來就像是個陣列,但是當我們要對物件管理器作巡訪時就不能像在對陣列巡訪那樣,簡單的只用個索引跑迴圈從頭到尾掃過每一個元素。考慮到效率的問題,巡訪的操作需要另外設計,最好每次巡訪容器時只會訪問到使用中的物件,完全訪問不到未使用的物件,同時還要兼顧到操作的效率。
ObjectPool pool; // 宣告物件容器
// 配置一些物件...
//
// 訪問物件容器
//
for (int i = pool.first(); -1 != i; i = i.next(i)) {
// 操作物件 pool[i]...
}
在上面的範例中看到,巡訪的動作主要是透過 first 和 next 二個函式達成。first 的作用是取得第一個已配置的物件索引值,而 next 則用來取得下一個已配置的物件索引值。我們還可以發現到,在前面我們設計的代表無效的索引值-1在這邊又派上了用場。如果 first 或者是 next 的回傳值是-1的話,則表示巡訪動作已結束,即找不到下一個已配置的物件索引值,此時迴圈就會遇到終止條件而跳出。
附帶提一下,在實際訪問物件容器時,有一個可能會發生潛在問題的狀況。那就是當我們一個一個訪問物件容器中的物件的過程中,對物件的操作也有可能造成物件的釋放。當在訪問過程中發生物件釋放的情況時,訪問物件容器的迴圈的下一個物件的索引值可能變成一個無效的值。因為我們是以一個物件索引值來取得它的下一個物件索引值,如果此物件索引值己經是無效值,則回傳的下一個物件索引值也會是無效值。如果程式繼續以此無效的索引值對物件容器執行後續的操作時,就有可能會發生預期之外的程式錯誤。
for (int i = pool.first(); -1 != i; ) {
int next = pool.next(i); // 事先把 next 索引值記錄下來
// 操作物件 pool[i].(此操作有可能造成物件i被釋放)
i = next; // 完成以上操作後再指定 i 為事先記錄的索引值
}
如上面範例所示,解決此問題的方法也很簡單,只需要稍微調整一下訪問物件容器的方式即可。訪問物件容器的迴圈中,每次操作目前物件 i 之前事先把物件 i 的下一個物件的索引值儲存起來。等到完成物件 i 的操作之後,再把事先儲存的下一個物件索引值指定為 i 作為下次操作的物件索引值。這樣無論原本索引為 i 的物件是否因為上一回操作而被釋放,都不會影響後續物件的操作,因而就避開並解決了此問題。
根據前面的設計,因為所設計的物件容器的主要操作和陣列一樣,使用陣列來作為內部的資料結構是最直覺的選擇。使用陣列的話,就可以很簡單的實現以索引值作出物件快速存取以及有效的記憶體使用的功能。但是對於配置、釋放及巡訪的功能,單純只以陣列原本的操作來支援的話,反而會變成沒有效率的操作,因為這三個動作每次執行時都需要從陣列的頭開始,以一個一個檢查的方法來找到是否可用或不可用的位置。因此有必要另外再設計其它的結構來支援這三個操作,以提升操作效率。
為了解決配置、釋放及巡訪操作的效率問題,使用串列 (linked list) 是一個可能的解決方法。需要在內部另外維護二個串列結構,這二個串列分別為未使用物件串列,以及已使用物件串列。
可以使用陣列結構來模擬實作出串列資料結構,同時對於這二個串列,還需要分別各使用了一個指標指向串列的第一個物件位置,透過這個指標才有辨法找到構成整個串列元素。
容器內部除了維護上述未使用物件串列和已使用物件串列之外,還可以另外維護了一個陣列。這個陣列的功用是用來快速的檢驗某個物件是否正在使用,因此只需要維護一個簡單的旗標陣列即可。有了這個標記,就能夠快速的檢驗某個物件是否正在使用中,而不必透過已使用串列,一個一個物件去比對。
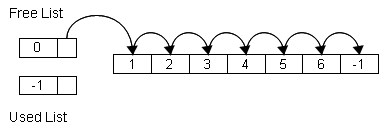
未使用物件串列的大小,在物件容器初始化時初始化成和物件元素陣列一樣大的,作成一一對應的關係,初始化時容器中的每個物件都是未被使用。串列的頭內含值為0,表示第一個未使用的元素在第0個位置,而第0個位置元素的內含值為1,表示下一個未使用的元素位置在第1個位置,依此類推。根據前面的定義最後一個元素內含值為-1表示串列的結尾。以一個大小為7個元素的串列為例,完整的未使用元素串列為:0 → 1 → 2 → 3 → 4 → 5 → 6。如下圖所示。

要配置取得一個未使用物件位置非常容易,只需要取得串列的頭即可。如果串列的頭內含值為-1則表示已沒有任何可用的位置,否則則回傳其內含值為配置結果,同時更新其內容為下一個所指目標值,如下圖所示。

因為原來第一個未使用的物件位置是0,取出使用後指向串列開頭的位置就變為位置0的下一個,也就是位置1。因此整個未使用元素串列變為:1 → 2 → 3 → 4 → 5 → 6。
釋放的動作只需要找到目前未使用物件串列的尾巴,將釋放掉的物件位置,銜接到串列的尾巴後面,成為新的尾巴,即完成了物件的釋放動作。物件被釋放後,因為它又被接回未使用物件串列上,也就意謂著這個物件又擁有被重新配置的機會。
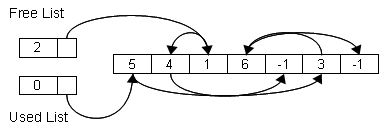
假設一個未使用串列為:1 → 2 → 5。

現在要歸還位置0這個被標示為已使用的物件,操作結果如下圖所示。

未使用串列變為:1 → 2 → 5 → 0,可以看到被釋放的物件總是被補到串列尾端。
物件容器剛建立時的初始化狀態,和未使用物件串列正好相反,所有物件都是標示為未使用,已使用物件串列的內容是空的,串列的開頭內含值為-1,如圖所示。

從未使用物件串列配置取得一個物件的操作,在未使用串列的變更動作已在上節中說明。接續上節的範例,因為配置的結果取得位置0的元素,我們需要更新已使用串列,先將配置得到的物件位置內容值更新為串列頭的內容值 (–1),接著再更新串列頭的內含值為配置得來的位素位置值 (0),使用串列為:0。結果如下圖所示。

如圖所示,在釋放物件之前使用串列的內容為:3 → 0 → 4 → 6。

釋放0的操作中,需要把原本指向位置0的指標改為指向原位置0所指的下一個位置,此例為4,變更後的串列內容為:3 → 4 → 6,如下圖所示。

在前面的章節裡面,我們分別對未使用物件串列及已使用物件串列的配置及釋放操作作了一個討論,下表列出對於這二個串列的配置及釋放操作所對應的串列資料結構的操作。
| 未使用串列 (free list) | 已使用串列 (used list) | |
|---|---|---|
| 配置 (alloc) | 刪除串列頭結點 | 加入至串列尾端 |
| 釋放 (free) | 加入至串列尾端 | 刪除串列結點 (任何位置) |
可以看到在這幾個操作裡面,只有未使用串列的配置操作是最簡單的,只需要花費單位時間 O(1) 即可完成操作。至於其餘三個操作,都需要花費和整個串列大小有關的時間複雜度 O(n) 才能完成操作。因為根據前面章節的討論,目前只使用一個指向串列開頭的指標來巡訪整個串列。因此如果要將結點加入到串列尾端的話,只能從串列的第一個結點開始巡訪,直到找到串列尾端為止才能完成操作。
要解決這個問題一個最簡單的方法是,將原來未使用物件串列及已使用物件串列所使用的串列結構,以雙向的串列 (double linked list) 結構取代。在雙向的串列裡,每一個節點都有指向前一個及後一個節點的指標,也會有另一個指標指向串列的尾端,這樣子對於插入及刪除串列裡任一節點的操作就能變成單位時間 O(1)。這是以空間換取時間的解決方法,因為這都是基本的資料結構,有許多相關資料可以作參考,在實作上也不會增加太多複雜度。
Object Pool 是一個泛型容器 (generic container),將物件的型別參數化之後,就可以適用於任何型別的物件,但所有的操作還是不變的,差別在於操作的是不同型別的資料物件。因為是容量固定大小不變的容器,所以容器的大小也是作為容器的初始化的參數之一,在初始化時就需作指定且初始化完成後便不再改變。
底下是根據前面章節所討論所作的 Object Pool 的 C++ 類別定義。
template<class T, size_t POOL_SIZE>
class ObjectPool
{
public:
T m_Entity[POOL_SIZE]; // object pool
int m_NumUsed; // 目前使用中的物件個數
int m_Free1, m_FreeN; // free list 的頭及尾
int m_Used1, m_UsedN; // used list 的頭及尾
int m_NextList[POOL_SIZE]; // free list 及 used list 的 next list
int m_PrevList[POOL_SIZE]; // free list 及 used list 的 prev list
int m_UsedList[POOL_SIZE]; // 已使用物件標記
int alloc(); // 配置一個物件
void free(int id); // 釋放一個物件
bool isUsed(int id); // 檢驗一物件是否為使用中
int first() const; // 取得第一個 used list 項目
int next(int id) const; // 取得下一個 used list 項目
};
m_Entity 是 Object Pool 內真正存放物件實體 (instance) 的地方,宣告成一個固定大小的陣列,陣列的大小在容器初始化時以 POOL_SIZE 參數指定,之後就一直是這個大小不再改變,物件的存取則限制只使用 m_Entity 陣列,且不斷的重複使用。
已使用串列及未使用串列都是雙向串列,在實作上把所指的二個不同方向拆開成二個子串列。一個叫作 Next List,串列裡每一個元素都指向下一個元素的方式作串列。另一個叫作 Prev List,串列裡每一個元素都以指向前一個元素的方式作串列。這二個串列分別以陣列 m_NextList 及 m_PrevList 實作,陣列的大小也和 m_Entity 一樣。m_NextList 及 m_PrevList 陣列的每個元素的值,都是對應到 m_Entity 上的物件索引值。m_UsedList 則是用來標記一物件是否是已配置,陣列大小也同於 m_Entity。
這裡在實作上有個小技巧。以 Next List 為例,在容器初始化時,所有物件都是在未使用串列內,所以 Next List 內所有元素都是未使用串列內的元素。隨著程式的進行配置了一些物件,所以已使用串列也開始有元素加進來。在 m_NextList 這個陣列內同時存在二個串列,分別是未使用串列及已使用串列的 Next List。這並不會有衝突,因為全部的元素加起來就 POOL_SIZE 這麼多,每一個元素不是在已使用串列中就是在未使用串列中,且每一個元素的索引都是保證唯一的,所以我們才有辨法在 m_NextList 內同時放進二條串列。
以下圖為例,一個容量為7個元素的容器初始化時,所有元素都是未使用串列的元素,所以已使用串列是空的,未使用串列串列為:0 → 1 → 2 → 3 → 4 → 5 → 6。
經過一段時間的使用之後,未使用串列內容變為:2 → 1 → 4,而已使用串列的內容則變為:0 → 5 → 3 → 6。這二個串列不衝突的同時存在一個陣列內。
以上我們討論了物件容器的基本操作,配置/釋放物件以及巡訪容器。除了這幾個基本操作之外,還能夠再定義其它的操作讓物件容器在應用上可以滿足更多需求,更加的有彈性。這一節的內容,會探討幾種可能的應用,但不提供相關實作細節。
動態改變容量目前這個物件容器是被設計成固定容量 (capacity) 大小的,所以可以動態的改變容量這個功能是首先會被考慮到的,假如容器可以擁有可以在執行時期改變大小的能力,在使用上將可以滿足更多的需求。畢盡不是所有的應用都能夠事先評估出物件的數量而定義出固定大小的容器容量,可以在執行時期時動態的改變容器大小,對於記憶體的管理上會更加有效率。
Object Pool 的內部資料結構主要是以陣列為主,因此動態配置容器大小的策略就比較容易作選擇,其中一個簡單的方法是,可以在每次物件配置失敗也就是無可用物件時,將容器容量以二倍於目前大小的方式成長。因為物件容器擁有能夠自動增長的能力,因此除非系統記憶體用罄,否則配置物件的動作是不可能會失敗,這點是需要注意的。
配置指定位置的物件當配置物件的操作成功時會回傳物件的位置索引值,新配置得到的物件會被加入到已使用物件串列中,因此實際上對於這個物件的位置是在那裡並無所謂,它可以在容器的任何位置。根據這點特性,因此就產生了一個想法:配置指定位置的物件。
那麼這個功能可以怎麼應用?這個功能可以應用在物件的永續儲存 (object persistence) 上。假如物件 ID 也是需要被儲存的資料欄位,那麼這個功能就會變的很重要了。有了這個功能,就可以直接以先讀取到的 ID 作物件的配置,配置成功之後再讀取其它欄位資料。少了這個功能的話,物件載入後它的配置得到的 ID 就不能保證和原來的一樣,若是又要和其它物件之間有關聯的話,問題就會變的更複雜。需要設計其它機制來解決這個問題,比如說不是以物件 ID 作關聯,而是以物件名稱來作關聯。
改變串列次序假如需要對已配置的物件作排序 (sort) 操作,則這個功能就有必要提供,否則只能另外再以額外的資料結構來儲存物件的次序資訊。這個功能只是很簡單的把兩個指定的物件,在已使用物件串列裡的位置對調 (swap),改變次序。
在第三章中我們完成了 STGE 腳本語言的設計,而在本章中我們將要實作一個可以執行 STGE 腳本語言的虛擬機器 (virtual machine)。按照正常的方法,我們會需要一個可以剖析 STGE 語言的語言剖析器 (parser),將寫好的 STGE 語言腳本 (script) 解譯成虛擬機器可以執行的內部形式。就好比我們需要一個C語言編譯器 (compiler) 將我們的C語言程式碼 (source code) 編譯成可以在 x86 平台(或其它平台)上執行的程式。為了簡化這個工作,我們採取了一個較簡單的方法,讓我們可以以某種形式在程式裡直接寫出可以在 STGE 虛擬機器可以直接執行的程式碼。這樣一來,我們就能夠在擁有一個 STGE 語言剖析器之前就能對 STGE 虛擬機器作測試。
採用這個方法的好處是,一旦我們完成了這樣的 STGE 虛擬機器實作,將來我們在實作 STGE 語言剖析器時,只需要將載入的 STGE 語言腳本編譯或翻譯成同樣的形式,就能在 STGE 虛擬機器上面執行。這個中間形式,若以 Java 語言來作類比的話,就相當於 Java 編譯器所輸出可以在 Java 虛擬機器 (JVM) 上執行的中介程式碼 Java bytecode。當然這只是一個概念上的類比,實作上跟 JVM 或 Java bytecode 還是有所差距。
第一步我們需要有個方法,將 STGE 程式轉化為我們虛擬機器可以執行的內部格式。底下我們從一個很簡單的範例開始。
script test direction(rand(360)) speed(rand(140, 180)) fire() end
這是一段很簡單的 STGE 程式片段:程式區塊 test 只包含三條指令,指定射擊方向指令 (direction)、指定射擊角度指令 (speed) 以及射擊指令 (fire)。direction 指令有一個 rand 參數,rand 參數其實又是一個函式呼叫,有一個參數360。speed 指令也帶一個 rand 參數,rand 呼叫又帶了二個參數。
為了簡單起見,我選擇了一個比較接近直譯式 (interpreted) 的方式來作轉換,因為這種方式最直覺,實作起來也最容易,看看下面的 C++ 虛擬碼 (pseudocode) 就可以理解為何會說是接近直譯式的轉換。
Script test;
test.append(Direction("rand(360)"));
test.append(Speed("rand(140, 180)"));
test.append(Fire());
上面的虛擬碼片段針對原始的 STGE 腳本指令作了一一對應的轉換,將每一條不同的 STGE 指令對應為 C++ 類別物件。direction 指令對應 Direction 類別物件,speed 指令對應 Speed 類別物件,fire 指令對應 Fire 類別物件。而 direction 及 speed 指令的參數則直接整個原封不動當作字串參數傳遞給指令物件,讓指令物件在內部再作進一步的處理。透過這樣子的方式,我們就可以很簡單的將 STGE 程式轉化為 C++ 程式,並且可以編譯後直接執行。
再來看一個稍微複雜的例子。
script test
repeat(10)
direction(rand(360))
speed(rand(140, 180))
fire()
end
end
這個範例主要多了一個 repeat 區塊,這是一個子程式區塊。底下同樣來看看虛擬碼的轉換。
Script test;
Script &rep = test.append(Script("10"));
rep.append(Direction("rand(360)"));
rep.append(Speed("rand(140, 180)"));
rep.append(Fire());
上面的轉換也是很簡單直覺,repeat 區塊被視為另外一個程式區塊,所以和 test 區塊一樣使用 Script 類別來加入 test 區塊,rep 物件承接 append 回傳的程式區塊物件參考,接下來的指令都加到這個物件底下。這樣子就能以一個簡單的方法建立起程式區塊的樹狀結構,無論子程式區塊是並聯或巢狀串聯都能簡單的作轉換。
class Script
{
public:
int type;
std::list<Script> sc;
};
和在作虛擬碼設計時不同,實際的實作我們只定義一個類別 Script,其中有一個 type 欄位,透過這個欄位讓 Script 物件也能夠作為通用的指令物件。sc 欄位以一個 STL (Standard Template Library) 的 list 容器定義,作為 Script 物件的串列容器,可以包含指令集或子程式區塊,而子程式區塊裡又可以再包含指令集或其它程式區塊,這樣就能夠表現程式區塊的樹狀結構。經過簡化,我們可以只使用單一一個 Script 類別就可以應用於翻譯所有的程式區塊和指令,而不需要針對每一個不同的指令都定義一個對應的類別。
type 欄位表示的是節點的類型,對應的就是指令類型,定義如下。
Enum {
NOP = 0,
ROOT, // 程式進入點
REPEAT, // 迴圈區塊
OPTION, // 條件區塊
FORK, // 產生新程序
CALL, // 呼叫子程序
FIRE, // 射擊粒子
SLEEP, // 暫停
DIRECTION, // 射擊方向
SPEED, // 射擊速度
CHANGEDIRECTION, // 改變射擊方向
CHANGESPEED, // 改變射擊速度
CHANGEX, // 改變水平座標
CHANGEY, // 改變垂直座標
CLEAR, // 消滅粒子
USERDATA // 自訂資料
};
使用最後版本的 Script 定義後,以第二個例子作為例子轉換後的 C++ 虛擬碼如下。
Script test; test.sc.push_back(Script(REPEAT, "10")); test.sc.back().sc.push_back(Script(DIRECTION, "rand(360)")); test.sc.back().sc.push_back(Script(SPEED, "rand(140, 180)")); test.sc.back().sc.push_back(Script(FIRE));
利用這個簡單的設計,把 STGE 腳本直接翻譯為虛擬機器看的懂的格式的工作就算是完成了!使用這個方法的最大的好處就是,在還沒有完成 STGE 腳本語言程式剖析器 (parser) 之前,我們就能夠先以手動的方法在程式裡寫法符合虛擬機器能夠直接執行的 C++ 程式碼並作測試,這可以大大提早我們的測試工作。同時等到 STGE 語言剖析器完成後,也能夠很容易實作程式碼產生器來產生可以直接執行的 C++ 程式碼,或是產生建立可直接使用的內部資料結構的程式碼。
每一段程式區塊都是不包含執行狀態的指令及迴圈定義,只有當程式區塊被執行時才會有相關聯的執行狀態被產生出來。同一個程式區塊可以被執行多次,每一個執行實體都是獨立存在有並擁有各自的執行狀態。這點就好比是 C++ 類別 (class) 對應於 C++ 物件 (object) 的關係,又或者像是執行檔 (executable) 對應行程 (process) 的關係。我們可以將所有程式區塊透過一個管理器集中管理,以程式區塊的名稱作索引來存取特定的程式區塊。所以這個程式區塊管理器會是個關聯式的資料庫,鍵值 (key) 是程式區塊的獨一無二的名稱,而對應的值 (value) 是程式區塊。
typedef std::map<std::string, Script> ScriptManager;
程式的定義很簡單,我們透過一個 STL 的 map 容器來實作出關聯式的資料庫,使用字串作鍵值對應 Script 作關聯。
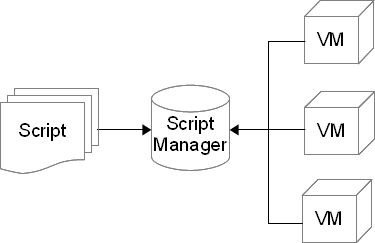
我們可以把 ScriptManager 看成是一個資料庫,它管理的內容是由腳本剖析器載入並轉譯後的 Script 物件。每一個虛擬機器在執行時期階段會指向一個參考的 ScriptManager,執行時期需要存取 Script 時都透過這個 ScriptManager。例如執行到一個帶子程序參數的 fire 指令時,動作程序會以這個子程序的名稱去向 ScriptManager 作 Script 物件搜尋,找到後再把這個 Script 物件和子程序物件作聯結。在實際應用上,我們可以產生多個虛擬機器,這些虛擬機器全部共用同一個 ScriptManager。當然也可以讓每一個虛擬機器各自擁有一個 ScriptManager,如何應用端看應用本身。
一個物件管理器 (object manager) 可以視為是虛擬機器:物件管理器管理二種物件,一種是粒子物件 (particle),而另一個則是動作程序物件 (action)。動作程序物件是 STGE 腳本指令的執行者,而粒子則受動作程序所控制。粒子具有實體 (instance),可以在畫面上佔據一個位置,且會移動。粒子的移動可以是自發的,也可以是受動作程序的帶動。假如移動中的粒子是被當作發射器 (emitter),則它的移動又會反過來影響動作程序的執行結果。
template<class ObjectT, class ActionT, int MAX_OBJ = 1024>
class ObjectManager
{
public:
const ScriptManager &smgr;
ObjectPool<ObjectT, MAX_OBJ> objs;
ObjectPool<ActionT, MAX_OBJ> acts;
int run(const std::string &name, float x, float y);
template<class PlayerT>
void update(float fElapsed, PlayerT &player);
};
ObjectManager 是個 template 類別,ObjectT 及 ActionT 參數分別表示作為粒子的物件類別及動作程序類別,MAX_OBJS 常數則是用來指定粒子物件及動作程序物件的 ObjectPool 的大小。因為我們設計的 ObjectPool 是事先就定義好大小,執行時期不會再動態改變容量,所以這個大小值需要根據應用的需求作定義,動作程序類別 ActionT 後面會再作詳細說明。物件管理器主要提供了二個方法,一個是用來啟動新動作程序的 run 方法,另一個則是用來驅動虛擬機器運作的 update 方法。
run 方法的第一個參數是個字串,表示要執行的 Script 名稱。第二及第三個參數是個座標值,表示這個動作程序的位置在那裡。因為在沒有關聯至任何粒子的預設情況下,一個動作程序被定義為關聯至一個虛擬的發射點,而這個虛擬的發射點的初始座標位置則由這二個參數來作指定,一旦動作程序啟動之後就能夠在腳本內自行改變自己的位置。run 方法回傳的值則代表這個新建立的動作程序物件的 ID 值,這個 ID 值也是在 acts 物件管理器裡的物件索引值。
int run(const std::string &name, float x, float y)
{
if (!ScriptMgr.find(name)) {
return -1;
}
int idAction = acts.alloc();
if (-1 == idAction) {
return -1;
}
acts[idAction].init(...);
return idAction;
}
以上是 run 方法的虛擬碼,首先檢驗指定的 Script 名稱是否有效,接著由動作程序物件管理器 acts 配置一個動作程序,成功後對新動作程序物件作初始化,最後回傳新動作程序物件 ID。過程中若有任何錯誤發生,則回傳代表無效的 ID 值-1。
遊戲應用程式在執行的過程中,在主迴圈內不斷的呼叫 update 方法來驅動虛擬機器運作,假如沒作這個呼叫動作,則所有物件便會靜止不動,動作程序也不會執行。每一次呼叫 update 方法,會執行所有運行中的動作程序,接著再移動所有作用中的物件。動作程序若結束執行時則會被釋放,物件則是被銷毀或移動範圍超出有效範圍之外則會被釋放,釋放出來的空間歸還給 ObjectPool,之後再被重複使用。
void update(float fElapsed, PlayerT &player)
{
//
// Update all active actions.
//
foreach action in acts {
if (!action.update(fElapsed, player)) {
freeAction(action);
}
}
//
// Update all active objects.
//
foreach object in objs {
if (!object.update(fElapsed, player)) {
freeObject(object);
}
}
}
如上面虛擬碼所列,update 方法作的事情很單純,真正的 update 動作由動作程序物件及粒子物件自己去完成。
作為 STGE 引擎與遊戲程式之間的介面,粒子類別是由應用程式定義,而由 STGE 引擎以 STGE 腳本控制產生並維護其生命週期。實際上遊戲程式還是能對粒子物件作操控,只不過大部份的情況下,遊戲程式只需專心負責如何在畫面上把這些粒子物件繪製出來呈現給玩家,而由 STGE 引擎來控制粒子物件的行為。
對 STGE 引擎來說,它只認識二種遊戲程式所定義的粒子類別。第一種是會被虛擬機器 (物件管理器)所管理的粒子類別,另一種是代表玩家自機的類別,它也被視為一種粒子並只會在虛擬機器作 update 時才被參考。在執行過程中,一般來說由虛擬機器所管理的粒子物件可以有很多,不同的虛擬機器也能各別管理自己的粒子物件,粒子物件在程式運行過程中會不斷的被產生或摧毀。而代表玩家自機的粒子物件只會有一個,可以讓所有虛擬機器共用。
STGE 引擎定義了一個基礎的粒子物件類別,遊戲程式可以不作修改直接應用或是繼承並改寫預設行為。這個類別只定義了二個方法及幾個必要的屬性。
class Object
{
public:
int idAction; // 關聯的動作程序 ID, 指向物件管理器的 acts 裡的物件
float x, y; // 目前的座標位置
float direction, speed; // 目前的移動方向及速度
float userdata[NUM_USER_DATA]; // 使用者自訂資料
bool init(ObjectManagerT &om, int idAction, int idNewObj);
bool update(ObjectManagerT &om, PlayerT &player float fElapsed);
};
idAction 是和粒子物件關聯的動作程序 ID,假如這個 ID 是有效的值,則表示這個粒子物件是受這個動作程序所控制。x 及 y 表示目前粒子物件的座標值,這是一組相對座標值,至於是相對於什麼座標系則需由遊戲程式作定義。direction 和 speed 則代表目前粒子的移動方向及速度,根據前面的定義移動方向的有效範圍為0到360度之間,而速度則定義為每移移動的 pixel 數,不過這個定義可以由應用程式重新定義。userdata 則是關聯至粒子物件的一組由應用程式自行定義應用的數據,總共有 NUM_USER_DATA 個不同的數據值可供應用。
//
// 回傳 true 表示粒子初始化成功,否則回傳 false 表示失敗且會立刻摧毀回收這個粒子
//
bool init(ObjectManagerT &om, int idAction, int idNewObj)
{
return true;
}
當虛擬機器產生一個新的粒子物件之後,會先對這個粒子物件作好內部的初始化動作,例如設定好它的初始座標位置及初始移動方向和速度等。接著會再呼叫粒子物件的 init 方法讓遊戲程式有機會再作其它部份的初始化動作,假如應用程式沒有再自定額外的初始化動作,那麼如上面所列的虛擬碼,預設的 init 方法會直接回傳 true 表示初始化成功。假如 init 方法回傳了 false,則虛擬機器會把初始化動作視為失敗,立即摧毀掉這個新生的粒子物件並且回收重複使用這個粒子物件。
//
// 回傳 true 表示一切正常,否則回傳 false 表示這個粒子必須摧毀
//
bool update(ObjectManagerT &om, PlayerT &player float fElapsed)
{
x += fElapsed * speed * cos(direction);
y += fElapsed * speed * sin(direction);
return true;
}
如上面的虛擬碼所示,預設的 update 方法的工作很單純的只是根據目前粒子的移動方向及速度計算並更新粒子的座標位置並且回傳 true,如果在 update 方法裡回傳 false 時,虛擬機器會自動摧毀掉這個粒子。STGE 引擎的虛擬機器並沒有定義任何碰撞之類的操作,所以改寫 update 方法在新的 update 方法裡實作一個自己的碰撞演算法是一個不錯的選擇。例如改寫 init 方法加上自己的 HP 屬性,再改寫 update 方法在裡頭作碰撞檢定決定是否擊落一代表敵機的粒子物件 (返回 false)。
STGE 引擎的動作程序在概念上和執行緒 (thread) 類似,為一真正執行指令的實體。想像一下在遊戲畫面上有許多粒子,有的代表敵機,有的代表敵機或自機所發射出來的子彈,有的是炸彈碎片或效果粒子等。每一個粒子物件都受一個掛載 (bind) 在它之上的一段 STGE 腳本所控制,不同的物件類型執行的腳本程式也不同。遊戲實際在執行的時候,我們在畫面上所見到的是所有的這些物件都是同時在運動中,每一個物件各有各自的不同行為。所以很自然的我們會把 STGE 腳本程式的執行實體類比成一個執行緒物件,即使這些執行緒物件在執行時,還是一個一個循序執行的假執行緒,但在概念上還是可以容易理解在畫面上所有物件是同時動作,相當於許多同步執行的執行緒,每一個執行緒各別控制一個物件的動作。
每一個動作程序物件就好像是一個小型的有限自動狀態機 (finite-state machine:FSM) 擁有自己的狀態,且狀態會自動推移更新。基本原理是每一個動作程序會有個 Script 物件的參考,指向實際要執行的腳本指令。還有個指令指位器 (program counter:PC) 指向當前正在執行的指令,以及其它狀態。每次執行完目前所指的指令之後,指令指位器會變更指向下一道指令,一直不斷的重複這個動作,直到執行完所有指令或執行了一道停止指令為止。
如圖所示,動作程序物件的執行程序參考到 test 腳本,指令指位器 PC 則指示出目前執行到 fire 這道指令。在動作程序物件裡,腳本內的指令是由動作程序物件來執行的,而流程的控制則落在指令指位器身上。
class Action
{
public:
int idThis; // Self ID
int idCaller, idCallee; // 父程序 ID 及子程序 ID
int idObj; // 關聯的粒子物件 ID
float x, y; // 發射粒子的初始座標
float direction, speed; // 發射粒子的初始移動方向及速度
float userdata[NUM_USER_DATA]; // 發射粒子的初始使用者自訂資料
int pc; // 程式指位器
float wait; // 暫停時間
bool update(float fElapsed, PlayerT &player);
};
以上是動作程序類別定義。動作程序類別最重要的方法就是 update 方法,這個方法負責控制程序的流程及執行指令,可以說是虛擬機器的核心所在。動作程序和粒子物件一樣,也維護了一份座標及移動方向和速度,還有使用者自訂資料。這一組屬性的作用是,當這個動作程序是作為一粒子發射器時,新產生出來的粒子會以這組屬性作為初始值。而 pc 為程式指位器,改變 pc 指向不同的指令相當於改變程式執行流程。例如程式循序執行、在迴圈或條件分支時,都是透過控制 pc 值來達成。wait 則是用於 sleep 指令控制暫停時間。
STGE 引擎將程式指位器抽離出來制定一個簡單的介面,在動作程序內透過一個指位器物件來獲得目前程式執行的位置,讓程式指位器物件處理掉流程控制的複雜瑣碎的工作,這樣動作程序就能夠專心負責處理各別指令的作業。
bool Action::update(...)
{
//
// 等待動作,等待子程序完成執行或暫停時間到達
//
...
//
// 執行指令
//
while (!pc.end()) { // 執行完畢?
switch (pc.curr()) // 處理目前執行的指令
{
case DIRECTION:
...
break;
case SPEED:
...
break;
case SLEEP:
...
return true;
...
}
pc.next(); // 下一道指令
}
return !pc.end(); // 執行完畢?
}
在上面這段虛擬碼裡,動作程序的 update 方法透過一個程式指位器物件 pc 的協助,一一執行它所關聯的動作程序。程式指位器物件 pc 在初始化時已先指定關聯至要控制執行的動作程序,並且設定好指向第一道指令。在動作程序的 update 方法裡的迴圈不斷的透過指位器的 end 方法檢查是否執行完畢,假如 end 方法回傳的值是 true 則跳出迴圈結束執行,否則透過指位器的 curr 方法取得目前的指位器所指的指令,根據指令類別作處理。
在上面的虛擬碼中還可以注意到,假如沒有意外的話 update 方法裡的這個迴圈會一口氣執行完所有的指令才跳出。除非執行到幾個特殊的指令,才會從中途跳出等待下次再進入 update 方法時,繼續執行完剩下的指令或直接結束動作程序。這幾個特殊的指令是:call、sleep 及 clear。call 指令因為呼叫了另一個子程序後,必須等待子程序執行完畢才能繼續執行下去,所以執行 call 指令啟動子程序後便立即跳出迴圈。sleep 指令因為設定了一個暫停時間,在暫停時間到達之前,整個執行狀態是處理凍結的,所以也是立即跳出。而 clear 指令是終止指令,所以不但立即跳出指令執行迴圈,同時也把動作程序物件一起終結掉。
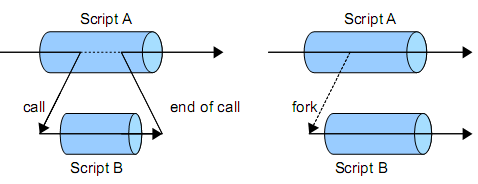
STGE 引擎有兩種呼叫子程序的方式分別為 call 及 fork,上圖對於 call 及 fork 呼叫的差別作了一個圖形化的說明。左側圖形中,當 ScriptA 以 call 指令呼叫了 ScriptB 後,流程控制轉移至 ScriptB,直到 ScriptB 結束執行後控制權才又回到 ScriptA。而右側的圖形中,當 ScriptA 以 fork 指令呼叫 ScriptB 後,ScriptB 啟動後 ScriptA 便繼續執行下去不作任何等待,相當於 ScriptB 啟動後就和 ScriptA 同步執行。
程式指位器在一個 CPU 或是虛擬機器裡擔任了很重要的任務,它的作用是用來標示目前執行指令的位置。一般情況下每執行完一道指令,程式指位器便會自動指向下一道指令的位置,依此方式循序執行完所有指令。不過這樣的程式幾乎很少見,一般的程式需要控制程式執行的流程來完成更複雜的任務。而改變程式指位器的值就相當於改變程式執行的流程,例如程式中的 if/else 條件分支,for/while 迴圈或 goto 等,都是以不同的方式改變程式指位器的值來達到控制程式流程。
上一節動作程序的 update 方法中指出,動作程序執行時流程的控制是由指令指位器來掌控。在 Action::update 執行指令的主要迴圈中可以看到,每一次的 update 都會一直不斷的執行指令直到告一個段落或者是整段動作程序執行完畢跳出。
class Cursor
{
public:
typedef std::list<Script>::const_iterator iter;
const Script* sc; // 目前執行的動作程序
iter cursor; // 目前指令位置
std::list<iter> curStack; // 目前程式堆疊
int count, repeat; // 迴圈計數器
std::list<int> repStack; // 迴圈計數器堆疊
const Expression::Context *ctx; // 算式狀態
const Script& curr() const;
bool end() const;
void next();
};
動作程序執行時流程的控制主要由程式指位器的 curr、end 及 next 三個方法來控制。curr 用來取得目前指令執行到什麼位置,而 end 則用來判斷是否己執行到動作程序的最後一個指令。next 根據目前指令位置以及堆疊狀態來決定下一條指令的位置,具體規則如下。
STGE 引擎裡的每一道指令的參數,除了作為子程序名稱的參數外其餘的參數都是算式。STGE 引擎的算式在第三章裡我們已作了詳細的定義,除了作基本的四則運算外,還可以運用由父程序傳遞過來的參數,以及粒子本身的相關屬性參數,以及最重要的亂數函數的使用等。
由以上的敘述可以得知,一個算式如果帶了變數時就無法在載入時就決定它的值,必須在執行時期才有辨法動態決定。因此算式是以原始字串的形式儲存著,一直到執行時期被參考到時才會作計算,以當時的狀態決定最終的值。但因為一個常數算式也有可能不包含變數的成份,如果已經可以確定一個算式是個常數,就可以只計算一次並把結果儲存下來重複使用,而不必每次讀取時再作一次重複的計算,當讀取的次數是很大量時,浪費就很明顯了。所以對於常數算式,我們可以對它多作一些最佳化的處理。
在實作上我們把指令參數也就是算式作了一層包裝,動作程序在讀取參數值時一律透過參數物件,而不是直接由動作程序自行去解析算式。這樣子的切分,參數物件就能在內部提供額外的處理,例如對於常數算式來說,當初始化時對它作取值的解析處理,之後就可以將這個值快取 (cache) 起來以利重複使用加速整體效能,這是以額外記憶體空間換取執行時間的技巧。而對於包含變數的算數而言,則和原來的處理沒有不同,每次讀取時都需要再作一次解析處理根據當前狀態決定新的值。
class Param
{
public:
bool bConst;
float valConst; // Constant Cache
std::string exp;
Param(const std::string &aExp);
bool isConst() const;
float operator()() const;
};
Param 類別是參數的包裝類別,讀取的方式透過覆載 (operator overloading) 的 operator(),實作相當直覺,假如這個參數是個常數則直接回傳快取的常數值,否則則即時對算式作運算求得一個值再返回。
float Param::opeartor() const
{
if (bConst) {
return valConst;
} else {
return Expression(exp).eval();
}
}
而快取的常數值則是在參數物件初始化時,透過 isConst 方法檢驗是否是常數算式,若是常數算式則將這個常數值儲存下來以利之後快速取值。
Param::Param(const std::string &aExp) : exp(aExp)
{
if (isConst()) {
bConst = true;
valConst = Expression(aExp).eval();
}
}
isConst 對算式作一個簡單的檢驗,這個檢驗根據我們的定義,只要算式內有任何$字符號我們就可以認為這個算式包含了變數,或是有任何其它非數字的字元存在則也表示為非常數算式。
bool Param::isConst() const
{
if (exp.find('$')) { // 包含了變數?
return false;
}
foreach (ch in exp) {
if (isalpha(ch)) { // 包含了非數字字元?
return false;
}
}
return true; // 這是個常數
}
彈幕射擊遊戲裡的各種華麗彈幕,都是以前面我們研究過的幾種基本方法,結合變化產生出來的。當看著畫面上各種具數學上形式的樣式圖形時,一定會讓人聯想到彈幕的生成和數學的關聯,而且也會有使用的數學一定很高深的想法。事實上,我們實際會使用到的數學非常的簡單,擁有國中程度的數學就足夠了。
粒子的位置是最重要的屬性,而移動的速度和方向會讓粒子移動改變粒子當前的位置。借用向量的概念,我們可以把移動速度和方向合起來看成是一個速度向量。每次移動時,把這個向量乘上時間差再加上目前粒子的位置向量就能得到新的位置。作實際的計算時,只需要分別計算出速度向量的水平方向及垂直方向的分量,再以求出這二個方向上的位移量並累加到目前的位置就能得到最後的結果,而這只需要使用到三角函數的基本運算就可以得到我們要的結果。
Pt+1 = Pt + tV ....... 1
如公式1,V 表示為粒子的速度向量,Pt 是粒子目前的位置位向,而 Pt+1 表示為粒子下一時刻的位置向量,t 則是經過時間。
目前我們手上有粒子的位置 x 及 y 二個變數,以及用來表示速度向量的移動速度 dir 和移動方向 speed 的二個變數。計算時,我們先以公式2及3求得速度向量的水平分量及垂直分量。
Vx = V cos(θ) ....... 2 Vy = V sin(θ) ....... 3
以移動速度 speed 代入公式2和3的 V,再以移動方向 dir 代入公式2和3的 θ,就能求得到速度向量的水平分量 Vx 及垂直分量 Vy。
S = Vt ....... 4
有了水平分量 Vx 及垂直分量 Vy 後再以公式4可以得到每一次的位移量,S 是以速度 V 移動 t 單位時間的位移量。接著再分別把水平方向及垂直方向以公式4計算得到的位移量,累加到粒子目前的位置來求得粒子最後的位置,如下列公式5及6。
x = x + tVx ....... 5 y = y + tVy ....... 6
根據前面針對粒子移動的推導過程,除了基本的四則運算之外,主要就是 sin 及 cos 這二個三角函數的使用了。雖然現代的電腦運算能力和以前比較起來已經是相當強了,甚至三角函數的運算指令都已直接內建在 CPU 內,但我們還是有必要對這部份作最佳化。主要的理由有二點:
雖然我們都是以浮點數儲存粒子的移動方向,但我們在應用上只需要以整數提供360個角度變化,就足夠使用來變化出複雜的彈幕,而不必要真的作到非常精確的角度。從這個想法上出發來看,我們就可以很容易的想到可以以查表的方法對三角函數作最佳化。
初始化階段我們可以先針對二個事先準備好的表格 (table),大小都是360個元素,分別用以0到359的角度值預先計算出 sin 及 cos 的值並儲存在表格裡。在執行時期,雖然角度是帶小數的浮點數,不過我們可以很簡單的將浮點數轉型並調整成0~360之間的整數,並拿這個整數值到 sin 表或 cos 表裡,很快的查出預先計算好的函數值。使用這個技巧,可以大大的提高運算效能,而對於精確度的損失則是在可以接受的範圍內。運算能力的提高,則意謂著我們可以在畫面上同時處理更多的粒子,以創造出更華麗的效果。
除了三角函數 sin 及 cos 的使用以外,我們還需要另一個三角函數的運算。這用運算被應用在,當我們要目瞄準自機發射粒子時,需要求出發射點指向自機的夾角。如下圖所示,要由 A 點朝 B 點射擊,必須知道二點間的夾角 θ。
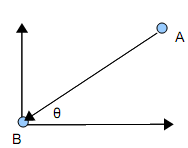
這個動作需要使用到三角函數的 atan 函數。atan 函數是 tan 函數的反函數,由水平及垂直分量反向求出原來的角度。這個運算我們就很難用查表的方式來實作了,不過還好有比較簡單快速且又不致失真太多的演算法可以使用。
在上一章裡,我們實作了可以執行STGE腳本的虛擬機器 (virtual machine)。我們可以在 C++ 程式裡面寫下相當於是 STGE 虛擬機器中介程式 STGE 語言的 C++ 程式碼,編譯完成後即可直接執行。但每次要改變腳本內容重新作測試,就相當於要改寫 C++ 程式並重新編譯執行,相當不方便。因此下一步就是實作一個可以載入以文字編輯器編輯好的 STGE 語言腳本 (script),透過 STGE 語言剖析器 (parser) 將腳本載入的轉換成 STGE 虛擬機器可以執行的中間碼。有了 STGE 語言剖析器之後,就不需要在每次測試時都要改寫程式,只需要在文字編輯器裡對 STGE 語言腳本作修改後儲存,再以 STGE 語言剖析器載入腳本轉譯成 STGE 虛擬機器中介程式就能立即作新的測試。
本章內容對語言剖析器相關技術及工具作一個介紹,學習如何製作一個文字剖析器,以及如何應用工具協助製作一個文字剖析器。本章分別介紹幾種常見的工具,實作一簡單的算式計算機作為學習範例。其中包含了,如何手工製作、使用 lex/yacc、使用 Boost Spirit 以及使用 yardparser 的協助來實作。
動作程序的啟動方法除了直接透過 ObjectManager 的 run 方法之外,其餘就只能在 STGE 腳本內執行 call、fork 及 fire 指令時才能動態的產生新的動作程序物件。我們現在只探討以 STGE 腳本指令產生新動作程序的狀況,因為這三個指令都是以一個動作程序來產生另一個新的動作程序,和 ObjectManager 的 run 方法在本質上有很大的不同。
call、fork 及 fire 指令都是在某一個動作程序內被呼叫的,我們把這某一個動作程序稱作為父程序 (caller)。父程序呼叫了 call、fork 及 fire 指令之後,會因為呼叫指令的不同而在狀態上有些許的變化。主要的差別在於:fork 和 fire 指令的執行結果可以歸為一類,這二個指令執行執行後產生出來的新的動作程序會脫離父程序獨立繼續執行,而 call 指令所產生出來的新的動作程式必須完成所有執行動作之後,父程序才能夠繼續往下執行下一條指令,在這之前父程序是處於凍結的狀態。
應用程式有時候會使用純文字 (text)格式的資料,例如常見的 XML (eXtensible Markup Language) 資料。而這些資料常常是經過格式化 (formated),因此載入時需要撰寫一段程式碼,專門用來分析這些經過格式化的文字資料,將讀入的文字資料轉換為應用程式在執行時期內部使用的資料格式。
轉換的動作主要分成二部份工作。首先會將讀入的文字資料串流 (stream) 分解,丟棄不需要的多餘字元如空白字元等,最後剩下為一個一個具有意義的小單位,通常這些文字小單位稱作為 token,這部份的工作由字彙分析器 (lexical scanner) 完成。接下來這些小單位再送給語法分析器 (syntax analyser) 作進一步的處理,語法分析器的工作是分析並找出這些小單位之間的關係。由字彙分析器及語法分析器的協同作業組成一個完整的語法剖析器 (parser)。
例如一個 C 語言的原始碼剖析器,載入 C 語言原始碼文件後,文字資料串流通過字彙分析器被分解為數字常數、標點符號、括號、變數名稱、函數名稱、字串等 token。接下來這些 token 被送往語法分析器作語法分析,語法分析器會比對這些 token 是否符合 C 語言的語法規則,最後再輸出結果產生抽象語法樹 (AST,abstract syntax tree),之後再作進一步的處理。
為了讓字彙分析器及語法分析器完成這些工作,需要告訴字彙分析器及語法分析器該怎麼作,也就是要告訴字彙分析器 token 是長什麼樣子,也要告訴語法分析器語法是什麼樣的組成,如此字彙分析器及語法分析器才能夠幫助我們分析及轉換文件資料。
BNF (Backus-Naur Form) 是由 John Backus 所開發,可用來表示與上下文無關文法的語言,也就是一種用來描述語言的中繼語言 (meta language)。一個 BNF 表示式是由一個非終端符號 (non terminal) 和它的產生式所組成,產生式可以是一個終端符號 (terminal) 和非終端符號組成的序列。(終端符號中的標點符號一般使用單引號括起來,而字串則使用雙引號)
底下為一個簡單的範例:
sent := subj verb '.' subj := "Birds" verb := "sing"
在上面的例子裡面,粗體字表示終端符號,如 Birds、sing 及句點 ('.')。而 sent 及 verb 表示為非終端符號。這條 BNF 句子定義了一條文法,表示的意思為,一個 sent 是由 subj 及 verb 再以一個句點為結尾所構成。
BNF 表示式有以下幾種主要表示形式:
(1) S := A B C
(2) S := A | B | C
(3) S := {A}
第一條表示說,S 是由 ABC 三個符號所定義, 而 ABC 是以序列的形式依序出現,也就是說 A 之後一定跟著一個 B,而 B 之後一定跟著一個 C。第二條表示說,由 S 可推導出 A 或 B 或 C 其中之一。第三條表示說,由 S 可以推導出一個或多個 A。
S := x A A := y | z (1) xy (O) (2) xz (O) (3) xx (X) (4) yz (X)
以上4個範例中,只有 (1)(2) 是符合上面 BNF 文法定義的句子,因為 x 之後只能接 y 或 z 所以 (3) 不符合文法,因為 S 只能以 x 開頭為句子所以 (4) 也文法錯誤。
id := alpha {alpha}
alpha := a | b | c | d
(1) aabbbcdd (O)
(2) cabbbda (O)
(3) baccab (O)
(4) bdax (X)
(5) 5acd (X)
在上面的5個範例裡面,其中 (1)(2)(3) 項是正確符合上面 BNF 的文法定義。而 (4) 因為 alpha 裡不包含 x 符號所以語法不正確。而 (5) 因為 alpha 裡面不包含5所以也不正確。
S := '-' FN | FN FN := DL | DL '.' DL DL := D | D DL D := '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9'
這幾條規則可以用來描述如3.14這樣的浮點數或如-3.14具有負號的浮點數。在 DL 這條規則裡面我們看到了它的定義中還出現了自己,用自己來定義自己的情況,也就是說這是一種遞迴的定義形式。雖然還是勉強能夠看的懂這些定義,不過還是有點不是那麼直覺易用,所以後來又出現了 BNF 的擴展形式 EBNF (Extended Backus Naur Form),EBNF 引進了底下幾個新的符號改進了這些問題。
| 符號 | 說明 |
|---|---|
| ? | 表示符號左方的符號 (或左方的括號中的一組符號) 是可有可無 (optional)。 |
| * | 表示符號左方的符號的數量可以出現0次以上。 |
| + | 表示符號左方的符號的數量可以出現1次以上。 |
所以上面的浮點數範例使用 EBNF 可以重新改寫成如下的形式。
S := ('-')? D+ ('.' D+)?
D := '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9'
這樣是不是變的簡單明瞭多了?其實 EBNF 並沒有比 BFN 強大到那裡,只不過和 BFN 比較起來在使用上更加方便而已,而所有的 EBNF 表示式都是可以轉換為 BNF 表示式的。
看過以上幾個簡單的範例之後,相信對 (E)BNF 表示式已經有了一個初步的理解,雖然對於完整的 (E)BNF 表示式還只是很初略的認識,不過有了這些基本概念之後已經有足夠的知識能夠理解接下來所要說明的內容。在了解如何定義語法後,就能夠寫下我們剖析器所要分析的資料的語法規則的 (E)BNF 表示式,然後再針對實作上的不同,將 (E)BNF 表示式轉換為實際的程式碼。
現在我們已經知道如何寫出基本的 (E)BNF 表示式來描述資料的語法規則,現在可以開始進入本章的主題 ,實作算式計算機。在開始實作之前,還需要完成算式計算機的語法規則的 (E)BNF 定義。
底下是我們的需求。
下面是一些符合這些要求的範例。
12345 +12345 -1 + 2 * 3 - 4 / 5.6 1 * 2 - 3 * (4 + 5) (1 + (2 + (3 + (4 + 5)))) 1.2 * 3.4 – 5.67 / 8
使用 EBNF 表示式寫下算式計算機的語法規則定義,如下所列。
group := '(' expression ')'
factor := integer | group
term := factor (('*' factor) | ('/' factor))*
expression := term (('+' term) | ('-' term))*
接下來本章剩餘的內容,將會使用幾種不同的方式來實作出符合上述幾條語法的算式計算機。其中可以看到如何使用純手工方式來打造這個算式計算機,也可以看到如何使用如 lex/yacc 或 Boost Spirit 等工具的協助來製作出算式計算機。
實作一個剖析器最簡單直接的方法就是使用遞迴下降 (recursive descent) 的技術,底下我們就來看看什麼叫作遞迴下降分析。
在前面對剖析器 (parser) 的簡介裡面提到過,一個剖析器的轉換工作主要分成二個部份:將讀入的資料串流分解為有意義的小單位 token,以及處理這些 token 間的關係。現在直接假設我們已經能夠得到分解完畢的 token了,接下來要作的工作就是分析這些 token 之間的關係,檢查它們是否符合我們定義的規則語法。
實作的方法相當的直接。首先從資料串流中獲取一個 token,接著檢查這個 token 是否符合目前正在檢查的語法的第一個符號,如果比對結果是符合的話,那麼就把當前的 token 給丟棄並再讀入下一個 token,接著再繼續拿這個 token 和規則的下一個符號作比對。在比對規則時,如果中間遇到了非終端符號,則這個非終端符號會再展開。一直重複這個動作直到讀完所有資料為止,比對的程序才結束。
底下以 group 這條規則來作說明,以下為虛擬碼。
// 檢查當前的 token 是否是我們所期望匹配的符號
void match(token)
{
if (current_token == token) {
current_token = get_next_token(); // 如果匹配成功則再讀入下一個符號
} else {
error(token + " token expected"); // 比對失敗報出錯誤
}
}
// 規則:group := '(' expression ')'
void group()
{
match('('); // 第一個符號需匹配 '(' 字元 (終端符號)
expression(); // expression 是另一條規則需在往下展開 (非終端符號)
match(')'); // 最後一個符號需匹配 ')' 字元 (終端符號)
}
以上的方法稱作為遞迴下降的分析技術,使用這樣的技術就可以很容易的把 (E)BNF 描述句轉成程式碼實作出來。
根據上一節介紹的遞迴下降分析技術,現在已經知道要怎麼把定義好的算式計算機 (E)BNF 規則實作出來,所以接下來的目的是要把上面定義的4條規則給變成可以執行的程式碼。首先是剛剛看已經看過的用虛擬碼實作的 group 規則,改寫成如下的 C/C++ 程式碼。
// 規則:group := '(' expression ')'
float group()
{
float val;
match('('); // 第一個符號需匹配 '('字元
val = expression(); // expression 是另一條規則需要往下展開
match(')'); // 最後一個符號需匹配 ')'字元
return val;
}
接下來是 factor 這條規則。
// 規則:factor := integer | group
float factor()
{
if ('(' == current_token) { // 是 group 規則的開始符號嗎?
return group(); // 以 group 規則展開
} else {
return get_number(); // 讀解出一個數字
}
}
factor 這條規則是由 integer 或 group 這樣的規則組成,其中 integer 是個終端符號而 group 是非終端符號,所以一開始先作一個檢查來判定目前讀到的 token 是不是 group 規則的開始符號,如果是的話就再以 group 規則展開,否則就直接讀取出一個數字來。
接著是 term 這條規則。
// 規則:term := factor (('*' factor) | ('/' factor))*
float term()
{
float val = factor();
while ('*' == current_token || '/' == current_token) {
if ('*' == current_token) {
match('*');
val *= factor();
} else {
match('/');
val /= factor();
}
}
return val;
}
最後是 expression 這條規則。
// 規則:expression := term (('+' term) | ('-' term))*
float expression()
{
float val = term();
while ('+' == current_token || '-' == current_token) {
if ('+' == current_token) {
match('+');
val += term();
} else {
match('-');
val -= term();
}
}
return val;
}
以上就完成了以純手工打造的算式計算機的語法剖析器。
lex (Lexical Analyzar) 及 yacc (Yet Another Compiler Compiler) 是用來輔助程式設計師製作語法剖析器的程式工具。lex 的工作就是前面提到過的,幫助我們將輸入的資料文字串流分解成一個個有意義的 token,而 yacc 的工作就是幫我們分析這些 token 和我們定義的規則作匹配。下圖中所表示的是使用 lex 及 yacc 的一般工作流程。
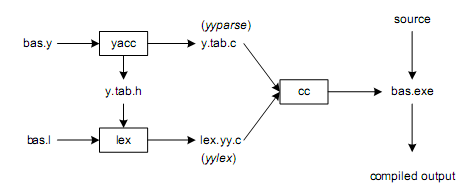
首先看到 yacc 會讀入一個 .y 檔案,這裡 .y 檔案的內容就是我們使用類似 (E)BNF 語法定義的語法規則,yacc 會分析這些語法規則後,幫我們產生可以用來解析這些規則的程式碼,而這個檔案一般名稱預設為 y.tab.c,產生的程式碼裡面最重要的一個的函式叫作 yyparse。
同 yacc 類似,lex 也會讀入一個 .l 的檔案,這個檔案裡面定義的是如何從文字流裡解出 token 的規則,使用的方法是正規表示式 (regular expression)。在圖的左側中間我們還可以看到有一個叫作 y.tab.h 的檔案從 yacc 產生出來並餵給 lex 作輸入,這個檔案是 yacc 根據讀入的 .y 檔裡面所定義的 token 代號所產生出來的一個 C/C++ header,這樣 yacc 及 lex 產生出來的程式碼裡面就可以使用共通定義的代碼而不必各寫個的。lex 分析過 .l 檔案後也會產生一個一般預設叫作 lex.yy.c 的原始碼檔案,裡頭最重要的一個函式叫作 yylex。
最後,我們把 yacc 產生出來的 y.tab.c 還有 lex 產生出來的 lex.yy.c,以及其它我們自己撰寫的原始碼檔案一起拿來編譯再作連結,最後產生出來的就是一個可以用來解析我們定義的語法的解析器工具。以上是整個 lex 及 yacc 的使用流程概觀。
在正式使用 lex 之前,需要先對正規表示式 (regular expression) 作一個基本的認識。正規表示式是一種用來表示字串樣式 (pattern) 的中繼語言 (meta language),好比前文所介紹的 EBNF 表示式一樣,都是用來描述其它語言的語言,只不過用途不同罷了。正規表示式使用一些中繼符號 (meta symbol) 以及 ASCII 字元定義字串樣式,以下列出一些正規表示式所使用的符號。
| . | 表示除了換行字元以外的所有其它字元。 |
| \n | 表示一個換行字元。 |
| * | 表示左方的字元或樣式可以是0個或多個。 |
| + | 表示左方的字元或樣式可以是1個以上。 |
| ? | 表示左方的字元或樣式可以是0個或1個 (可有可無)。 |
| ^ | 表示是在一行的開頭。或者在方括號內表示 [不包含]。 |
| $ | 表示是在一行的最後。 |
| a | b | 表示為 a 或 b 二者選一。 |
| (ab)+ | 小括號裡表示為一個子樣式,表示為有1個以上的 ab 組合。 |
| "a+b" | 字串常量 "a+b"。 |
| [] | 一組字元,表示為這組字元當中的任一個。 |
底下是一些範例,範例的左邊是樣式,右邊是符合樣式的字串。
| abc | abc |
| abc* | ab abc abcc abccc ... |
| abc+ | abc abcc abccc ... |
| a(bc)+ | abc abcbc abcbcbc ... |
| a(bc)? | a abc |
| [abc] | a b c (三者其中之一) |
| [a-z] | 任何 a 到 z 之間的字元 |
| [a\-z] | a - z (三者其中之一) |
| [-az] | - a z (三者其中之一) |
| [A-Za-z0-9]+ | 1個以上的大小寫英文字母及數字組成的字串 |
| [ \t\n]+ | 1個以上的空白字元 (包含空白,跳鍵及換行字元) |
| [^ab] | 除了 a 及 b 以為的任何字元 |
| [a^b] | a ^ b (三者其中之一) |
| [a|b] | a | b (三者其中之一) |
| a|b | a 或 b 其中一個 |
看過這幾個簡單的範例之後,相信對於正規表示式有了一個基本的認識。
底下以一個簡單的範例來示範如何使用 lex 作為練習,這個範例可以對一段文字作簡單的計算字元數、字數及行數。在開始之前先看看前面提到過的要輸入給 lex 的定義檔案內容是長什麼樣子。如下所示,我以看到一份定義檔案內容以符號 %% 分為三大區塊。
%{
... 定義 ...
%}
%%
... 樣式 ...
%%
... 程式 ...
定義區塊裡面放的是 C 語言程式碼,我們可以把和應用程式相關的定義或宣告放在這個區塊裡面。lex 載入定義檔為我們產生字彙剖析器的程式碼時,會原封不動的把這一區塊個的程式碼複製過去,不會對這部份程式碼作任何額外的加工處理。
樣式區塊是主要的重點區塊,裡面條列的使用正規表示式定義的樣式以及對應的動作程式碼,動作程式碼的作用等到稍後真正見到時再作說明。而程式碼區塊和定義區塊一樣,放置的也是我們自己的程式碼。lex 在最後為我們產生字彙剖析器的程式碼時也會原封不動的複製過去,而不作任何處理。
接下來底下列出計算字數行數範例所需要的定義檔。
%{
int nchar, nword, nline;
%}
%%
\n { nline++; nchar++; }
[^ \t\n]+ { nword++, nchar += yyleng; }
. { nchar++; }
%%
int main(void)
{
yylex();
printf("%d\t%d\t%d\n", nchar, nword, nline);
return 0;
}
在這份定義文件內,可以看到在定義區塊裡面有一行 C 語言的變數宣告,宣告了三個整數變數,nchar、nword 及 nline,分別用來代表接下來要計算文字內容的字元數、字數以及行數。在樣式區塊裡面定義了三個樣式,根據在上一節裡面學到的對於正規表示式的知識,可以知道這三條樣式所代表的意義。
| \n | 換行字元 |
| ^ \t\n]+ | 1個以上的非空白字元 |
| . | 換行字元之外的所有字元 |
要注意的是在樣式正規表示代的右邊以大括號括起來的程式碼,這就是前面提到過的動作程式碼。這是在字彙剖析器在分析字串作樣式匹配時,假如樣式符合且樣式有指定動作程式碼,也就是在樣式右側的程式碼,則這段程式碼就會被執行。
以 \n 這條樣式來說明,如果樣式匹配,則程式碼 { nline++; nchar++; } 會被執行。注意到這裡的大括號,假如動作程式碼只有一行的話,則大括號是可有可無的,像是第三條樣式。但我們一律還是都寫上大括號以免有所遺漏,同時也要注意的是不管動作程式碼有幾條指令,全部都要寫在同一行裡面。
最後是程式碼區塊,這區塊裡有個 main 進入點,第一行指令呼叫了 yylex 這個函式。在前面的介紹中,我們知道 yylex 是由 lex 自動產生的函式,這個函式的工作就是作字彙剖析,一直到結束後才會返回。返回之後,我們再把計算的字元數、字數以及行數列印到畫面上。
yacc 必須搭配 lex 一起使用,因為 yacc 主要的工作是作語法分析,而構成語法句子的 token 是由 lex 負責分析比對。和上一節同樣,底下透過一個簡單的範例來學習如何使用 yacc。這個範例要作的是,能從輸入文字串流中的每一行文字裡讀取0個或1個以上的數字,如果有超過1個以上的數字,則每個數字需以逗號分開,最後再把所有數字相加的結果列印到畫面上,直到結束輸入為止。
首先第一步驟是使用 EBNF 表示式把規則寫出來。
S := INTEGER (',' INTEGER)*
因為 yacc 的樣式區塊裡的樣式使用的是 BNF 表示式,所以我們要把上述的規則由 EBNF表 示式改寫成 BNF 表示式。
integers := INTEGER | INTEGER ',' integers
有了規則 BNF 表示式之後,接下來就可以寫出用來給 yacc 看的定義檔了。定義檔的格式和 lex 定義檔的格式類似,底下列出這個範例的 yacc 定義。
%{
int yylex(void);
%}
%token INTEGER
%%
lines
:
| lines integers '\n' { printf(" = %d\n", $2); }
;
integers
: INTEGER { $$ = $1; }
| INTEGER ',' integers { $$ = $1 + $3; }
;
%%
int main(void)
{
yyparse();
return 0;
}
上表是 yacc 定義檔,底下直接看樣式區塊部份。列表中在樣式區塊內共有二條樣式,第二條 integers 也就是前面寫下來的 BNF 表示式。除此外另外加了一條規則 lines,這條規則可以在執行測試的時候可以連續測試多行的資料,而不必每次測完一行資料就需要再重新執行程式。
現在要注意的是在樣式的右側的動作程式碼。和 lex 定義檔裡的動作程式碼一樣,統一使用大括號將動作指令括起來。在動作程式碼裡面可以看到像 $1、$2 還有 $$ 這樣奇怪的符號。在動作程式碼裡的這幾個符號是對應到樣式裡面的符號值,從左邊開始算來,第一個符號叫作 $1,第二個叫 $2,依此類推。而樣式左側,也就是樣式冒號的左側值則以 $$ 表示。
因此,在 lines 樣式裡的 $2 就對應 integers 這個值。預設情形下符號值的型別是整數,當然也可以使用其它型別的符號值,不過這不是這裡要談論的重點,有興趣的話可以參考 lex/yacc 相關書籍資料。lex 定義檔內容就不再表列出來。
了解 lex 及 yacc 的使用後,底下使用 lex 及 yacc 的協助實作出一個簡單的算式計算機。以下表列出 yacc 的算式計算機實作定義檔內容。
%{
#define YYSTYPE double
extern int yylex();
%}
%token NUMBER
%%
lines
:
| lines expression '\n' { printf(" = %lf\n", $2); }
;
expression
: term { $$ = $1; }
| expression '+' term { $$ = $1 + $3; }
| expression '-' term { $$ = $1 - $3; }
;
term
: factor { $$ = $1; }
| term '*' factor { $$ = $1 * $3; }
| term '/' factor { $$ = $1 / $3; }
;
factor
: NUMBER { $$ = $1; }
| group { $$ = $1; }
;
group
: '(' expression ')' { $$ = $2; }
;
%%
int main(int argc, char** argv)
{
yyparse();
return 0;
}
下表是 lex 定義內容。
%{
#include "y.tab.h"
%}
%%
[0-9]+"."[0-9]+ { sscanf(yytext,"%lf",&yylval); return NUMBER; }
[0-9]+ { sscanf(yytext,"%lf",&yylval); return NUMBER; }
[ \t] ;
[\n] { return '\n'; }
. { return yytext[0]; }
%%
int yywrap()
{
return 1;
}
Boost Spirit 是開源碼 C++ 程式庫 Boost 裡的一個項目,大量使用了 C++ Template Meta-Programming 實作技術。它提供了一個用來實作語言剖析器的框架,就好像 lex/yacc 一樣是專門用來製作語言剖析器的工具。但是 Boost Spirit 因為應用了 C++ Template Meta-Programming 的技術,使得我們可以在 C++ 程式碼中寫出相當於 EBNF 的描述且可直接編譯並執行,也因為如此 Boost Spirit 是一套既神奇又威力強大的工具程式庫。
按照慣例,我們要使用 Boost Spirit 來作個範例,透過一步一步的把範例實作出來的過程來學習如何使用 Boost Spirit。和上節一樣底下內容將以同樣的範例作示範,以 Boost Spirit 實作一個可以解析以逗號分隔的數字的語法剖析器,底下是這個語法剖析器的 EBNF 表示式。
S := INTEGER (',' INTEGER)*
雖然 Boost Spirit 可以直接把 EBNF 式以程式碼的形式直接寫在 C++ 程式碼內,但是因為受限於 C++ 程式語言的限制,有些表式法需要作些調動,底下列出幾個需要注意的地方。
A B
上面是原 EBNF 表示式的寫法,用來表示一個序列,A 之後會有個B。而在 Boost Spirit 裡需改寫成如下的形式。
A >> B
看起來沒有什麼太大的不同,也可以很容易的理解這是表示在 A 之後跟著 B 的序列。再來是 * 號的用法。
A*
在 EBNF 內,在符號 A 之後加個 * 號,表示 A 的數量是可重複的,可以是0個以上的 A 所構成的序列。而在 Boost Spirit 中需改寫成如下形式。
*A
正好相反,需要把 * 號擺到符號的前面,因為在 C++ 裡面並沒有任何後序式的 * 號運算元。不過就算改成前置式也不會影響到原來所代表的意義,並不會造成什麼衝突,容易理解。
A?
這是表示符號 A 是可有可無,也就是 A 的數量可以是0個或一個。以下改成以 Boost Spirit 的寫法。
!A
如你所見到的,問號變成驚嘆號,同時也提到前面變成前置式。那麼一個以上的表示式呢?一樣使用加號,也一樣改成前置式即可,如下所示。
+A
現在可以把上面所列的,用來表示以逗號分隔的數字的 EBNF 表示式,改成 Boost Spirit 的相容形式。
S = INTEGER >> *(',' INTEGER);
在上一節裡所看到的 EBNF 表示 S 式中的 INTEGER 以及逗號是終端符號。根據在 lex 及 yacc 的教學中知道,這些終端符號是由 lex 或具有 lex 功能,也就是字彙剖析器 (lexical scanner) 所解析出來再傳遞給語法剖析器 (syntax analyser) 的。在 Boost Spirit 中對應於 yacc 工具的語法剖析器功能就是在上一節中,可以直接在 C++ 程式碼中寫下 EBNF 表示式的功能,而對應 lex 的字彙剖析器的功能就是這節要介紹的內容。
在 Boost Spirit 中提供了許多內建的 parser,這裡的 parser 指的是字彙剖析器,例如整數的字彙剖析器、浮點數的字彙剖析器、字串的字彙剖析器,或字元的字彙剖析器等等,這些 parser 可以和上面的 EBNF 表示式一樣混合在一起直接使用。例如上例的 INTEGER 就可以使用整數 parser 來代換,而逗號就用字元 parser 來代換。
以下列出常用的 parser。
| int_p | 整數 |
| real_p | 浮點數 |
| ch_p | 字元 |
| str_p | 字串 |
| range_p | 字元範圍 |
| chseq_p | 字元集 |
| anychar_p | 任何字元 |
| alnum_p | 英數字元 |
| alpha_p | 英文字母 |
| space_p | 空白字元 |
底下舉幾個簡單的範例來作說明如何使用這些 parser。左邊是正規表示式,而右邊是 Boost Spirit 的寫法。
| abc | ch_p('a') >> ch_p('b') >> ch_p('c') |
| abc* | ch_p('a') >> ch_p('b') >> *ch_p('c') |
| abc+ | ch_p('a') >> ch_p('b') >> +ch_p('c') |
| a(bc)+ | ch_p('a') >> +(ch_p('b') >> ch_p('c')) |
| a(bc)? | ch_p('a') >> !(ch_p('b') >> ch_p('c')) |
| [abc] | chseq_p("abc") |
| [a-z] | range_p('a','z') |
看過以上幾個簡單的範例之後,相信對於 Boost Spirit 的 parser 有了基本的了解。現在可以把S寫成完整的 Boost Spirit 式 EBNF 表示式,如下所示。
S = int_p >> *(ch_p(',') >> int_p);
Boost Spirit 可以直接在 C++ 程式裡面使用 EBNF 表示式,至於在程式裡面要怎麼使用 S 呢?S 在程式裡面又代表什麼?
在 Boost Spirit 中 S 表示的是一個 Rule,它的型別是 rule<>,這是一般的表示式類型,事實上在 Boost Spirit 裡一個 rule<> 已經是一個可以工作的 Parser了。S 完整的定義如下。
rule<> S = int_p >> *(ch_p(',') >> int_p);
在 Boost Spirit 中有一個 parse 函數,使用 parse 函數我們就可以使用 S 來解析資料,使用方法如下。
bool parse_number(char const* str)
{
return parse(str, S, space_p).full;
}
parse 的第一個參數是文字串流 (stream) 來源,第二個參數就是我們提供的 rule (parser),而第三個參數也是個 rule,是專門使用來過濾空白字元的,一般我們直接拿 space_p 來使用就足夠了,如果還有更複雜的過濾需求的話再另外提供即可,例如另外提供一個專門可以用來過濾掉程式碼註解的 rule。
最後 parse 的回傳值是一個叫作 parse_info 的結構,在上例裡面只拿它的 full 欄位來使用。full 可以告訴我們解析的動作是否正常完成,即從資料來源的開頭一直解析到資料結尾都沒有任何錯誤發生。
現在已經知道怎麼使用 Boost Spirit 來實作一個 parser 了,不過這個 parser 還不怎麼有用,因為它還只能夠檢查資料是不是符合語法。至少還得像 lex/yacc 一樣還能夠插入我們自己的動作程式碼到 parser 裡面,這樣這個 parser 才能真正為我們作點什麼。
繼續拿上面的例子來作說明。
S = int_p >> *(',' >> int_p);
假如每當我們的 parser 解析出一個數字時,程式想要獲得通知以便把這個數字儲存起來,或者直接拿它來作點運算。在 yacc 裡面可以在二個 int_p 後面插入一段動作程式碼,而在 Boost Spirit 中也是一樣的作法,而且會更直覺。
S = int_p[&f] >> *(',' >> int_p[&f]);
上面的例子在二個 int_p 的後面各加了一對方括號,而在方括號中是個 &f。f 是個函數,使用這樣的語法告訴 Boost Spirit 當解析到一個 int 時呼叫我們指定的動作程式碼 f 函數。f 函數有一個 int 的參數,可以在 f 函數裡直接使用這個參數,這個參數就是 int_p 所讀取到的值。如果現在是使用 ch_p 則參數變為 char,依此類推。也可以使用一般型的動作程式碼函數,它的原型如下。
template<typename Iterator> void func(Iterator first, Iterator last);
Iterator 對應資料流的類型,例如 char*。這個函數帶有二個參數,分別是解析出來的 token 在資料流中開始及結尾的位置。你也可以一次使用好幾個動作程式碼在同一個位置,例如下面的例子一次呼叫三個函數。如果指定二個以上的動作程式碼的話,它們會以左至右的次序被呼叫。
S = int_p[&f1][&f2][&f3];
呼叫函式也能是個 functor (仿函式),它的原型如下。
struct myfunctor
{
template<typename Iterator>
void operator()(Iterator first, Iterator last) const;
};
使用方法如下。
S = int_p[myfunctor()];
根據前面的介紹知道了如何使用 Boost Spirit 來製作 parser 的相關知識,現在可以正式拿 Boost Spirit 來實作一個算式計算機。首先我們把表示算式計算機的 EBNF 表示式改成以 Boost Spirit 相容形式的表示式,工作就已經算是完成一大半,如下所示。
rule<> group, factor, term, expression;
group = ch_p(',') >> expression >> ch_p(',');
factor = int_p | group;
term = factor >> *((ch_p('*') >> factor) | (ch_p('/') >> factor);
expression = term >> *((ch_p('+' >> term) | (ch_p('-') >> term);
接著再加上 parse 函式的使用,就已經是一個可以運作的算式計算機程式了,剩下的只要再補上動作程式碼,用來處理真正的數值運算,整個程式就可以完成。底下列出不包含動作程式碼,但可以實際動作的程式列表。
#include <iostream>
using namespace std;
#include "boost/spirit/core.hpp"
using namespace boost::spirit;
int main()
{
rule<phrase_scanner_t> group, factor, term, expression;
group = ch_p('(') >> expression >> ch_p(')');
factor = int_p | group;
term = factor >> *((ch_p('*') >> factor) | (ch_p('/') >> factor));
expression = term >> *((ch_p('+') >> term) | (ch_p('-') >> term));
string str;
while (getline(cin, str)) {
if (str.empty() || 'q' == str[0] || 'Q' == str[0]) {
break;
}
if (parse(str.c_str(), expression, space_p).full) {
//
// Parsing succeeded
//
cout >> "Parsing succeeded\n";
} else {
//
// Parsing failed
//
break;
}
}
return 0;
}
把這個程式拿來編譯後執行起來試看看,它可以用來檢驗一個算式的正確性。接著再加上動作程式碼,讓它可以作真正的運算,計算出最後的結果。前面學過動作程式碼的形式及如何撰寫動作程式碼,底下就以前面所學寫下四個分別用來計算加減乘除以及一個用來儲存得到的數字的動作程式碼,另外再配合一個用來模擬堆疊的 C++ vector 容器。
vector<int> v;
void push_int(int i)
{
v.push_back(i);
}
void do_add(char const* first, char const* last)
{
int a, b;
a = v.back(), v.pop_back();
b = v.back(), v.pop_back();
v.push_back(b + a);
}
void do_sub(char const* first, char const* last)
{
int a, b;
a = v.back(), v.pop_back();
b = v.back(), v.pop_back();
v.push_back(b - a);
}
void do_mul(char const* first, char const* last)
{
int a, b;
a = v.back(), v.pop_back();
b = v.back(), v.pop_back();
v.push_back(b * a);
}
void do_div(char const* first, char const* last)
{
int a, b;
a = v.back(), v.pop_back();
b = v.back(), v.pop_back();
v.push_back(b / a);
}
這裡所使用的方法和在學習資料結構與演算法時用來處理算式的方法一樣,也就是將算式由中序式轉換為後序式,然後再配合堆疊,就可以很容易的把算式結果計算出來。這部份的原理就不再這裡再複述一次,有興趣的話自行參考相關資料。最後再把動作程式碼插入到 rule 內,整個 parser 就完成,如下所示。
group = '(' >> expression >> ')';
factor = int_p[&push_int] | group;
term = factor >> *(('*' >> factor)[&do_mul] | ('/' >> factor)[&do_div]);
expression = term >> *('+' >> term)[&do_add] | ('-' >> term)[&do_sub]);
另外補充一點。上面這幾行的 rule 裡面沒有再看到 ch_p 的使用,那是因為 Boost Spirit 已經有對一些 operator 作針對字元參數的覆載 (overload),所以就可以在程式碼裡省略掉 ch_p 的撰寫。不過在有些情況下,C++ 編譯器還是會找不到正確的 operator 函式,當這樣的情況發生時,只需明確的寫上 ch_p 即可。或者為了避免這樣的情況發生,也可以一律都用統一的寫法加上 ch_p。
yardparser 在使用上雖然沒辨法像 Boost Spirit 一樣那麼直覺便利,可以將 EBNF 語法規則直接定義在程式裡建立解析器,但使用類似的手法一樣可以將 EBNF 語法規則轉換為程式定義,建立一個語法解析器。yardparser 也沒辨法像 Boos Spirit 那樣,可以在執行時期 (run-time) 動態的改變或產生新的解析器。除了上述的不同處之外,最大的差異是 yardparser 的編譯時間非常短及以 yardparser 建立的 parser 執行速度非常快,同時產生的目的碼大小 (code size) 也相對小很多。
Boost Spirit 因為大量使用了 C++ Template Meta-programming 的相關技術,很完美的將 EBNF 語法規則語句嵌入到 C++ 程式碼內和我們所寫的程式碼結合在一起,相當直覺也相當神奇。只不過如果從得到的編譯時間和執行效率來看,只能說 Boost Spirit 為我們提供了相當出色的語法糖 (syntactic sugar),對於大型複雜的語法來說反而較難以適用。而 yardparser 雖然在使用上不如 Boost Spirit 那樣直覺便利,但至少在編譯時間和執行效率是大大滿足我們日常工作的需求。
底下同樣以簡單範例開始,介紹 yardparser 的基本使用。
A B
上面是原 EBNF 表示式的寫法,用來表示一個序列,在 A 之後會有個 B。而使用 yardparser 則寫成如下的形式。
struct AB : CharSeq<'A', 'B'>
{
};
CharSeq 是 yardparser 裡面事先定義好的一個 struct,作用是對輸入來源串流讀入字元來進行匹配動作。
(AB)*
以上定義了零個以上個 AB 序列的 EBNF 表示式的寫法,底下一樣轉換成 yardparser 的寫法。
struct StarAB : Star<AB>
{
};
AB 是上一個例子裡定義,用來匹配 AB 序列的規則。而 Star 是 yardparser 事先定義的一個 struct,把 AB 作為它的參數,就能夠用來匹配零個以上的 AB 序列。
(AB)+
類似 Star 的語法,Plus 是匹配一個以上的規則。
struct PlusAB : Plus<AB>
{
};
以上的規則定義用來檢驗匹配至少有一個以上的 AB 序列。
(AB)?
加上問號 (?) 表示這條規則是可有可無的 (optional),或者換句話說 AB 序列出現的次數可以是零次或一次。轉換成 yardparser 的語法,如下所示。
struct OptionalAB : Opt<AB>
{
};
yardparser 也內建了許多有用的 parser,這些 parser 或規則都以 C/C++ 的 struct 型式定義,主要可分為二大類。一類是基本規則,如 CharSeq、Star、Plus 等。另一類是 parser 類,如 Digit、AlphaNum、Word 等。除此之外包含於 yardparser 的範例中也內建了完整的C語言語法可以直接拿來應用,如 DecNumber、Tok、Literal 等。
底下列出常用基本語法規則。
| Seq | 匹配序列 |
| CharSeq | 匹配字元序列 |
| CharSet | 匹配其中一個字元 |
| CharSetRange | 匹配字元範圍中的一個 |
| Star | 零個以上匹配 |
| Plus | 一個以上匹配 |
| Opt | 零個或一個匹配 |
| Not | boolean not |
| Or | boolean or |
| True_t | boolean true |
| False_t | boolean false |
底下是一些簡單的範例。
| ab | struct AB : CharSeq<'a', 'b'> {}; |
| abc | struct ABC : CharSeq><'a', 'b', 'c'> {}; |
| abc* | struct ABandCstar : Seq<AB, Star<Char<'c'> > > {}; |
| abc+ | struct ABandCplus : Seq<AB, Plus<Char<'c'> > > {}; |
| bc | struct BC : CharSeq<'b', 'c'> {}; |
| a(bc)+ | struct AandBCplus : Seq<Char<'a'>, Plus<BC> > {}; |
| [abc] | struct AorBorC : CharSet<'a', 'b', 'c'> {}; |
| [a-z] | struct AtoZ : CharSetRange<'a', 'z'> {}; |
下面是定義在 yardparse 內建的 c_grammer 內的常用 parser。
| WS | 空白字元 |
| DecNumber | 實數 |
| HexNumber | 以 0x 開頭定義的十六進制數字 |
| CharTok | 匹配字元,以空白字元斷開 |
| Literal | 字面常數,包含數字文字等 |
yardparser 加入動作程式碼的方式和 Boost Spirit 的方式並不相同。底下以一個簡單的例子作比較,分別使用 Boost Spirit 及 yardparser 實作如下所列的簡單規則。
S = integer
底下是使用 Boost Spirit 的實作。
void get_int(int i)
{
}
rule<> S = int_p [&get_int];
可以看到以 Boost Spirit 實作的 S 解析器中,語法及動作程式碼的部份是各自獨立的。我們可以很容易的把動作程式碼 ([&get_int]) 的部份從語法 S 裡去掉,rule S 仍然可以運作,因此在真正為語法加上動作程式碼之前就已經可以開始對語法作測試,因此可以等到所有語法都完成實作後再回過頭來加入動作程式碼。
現在再來看看 yardparser 對 S 的實作。
struct Integer
{
};
struct Factor : Or<Integer, ...>
{
};
從上面的範例中可以看到,yardparser 的動作程式碼定義形式和一般的語法定義形式是同樣的,也就是在 yardparser 中動作程式碼可以視為是一特殊的語法解析器,它並不是用作在語法的匹配上,而是用於執行對應於語法規則上的操作。以上所示範例是一個最簡單的情況,而實際上常見的情況是動作程式碼會和語法規則夾雜在一塊,這在最後實際實作算式計算機時即可見到,在這方面 yardparser 和 Boost Spirit 比較起來就沒那麼簡單直覺。
現在來看看 yardparser 的 parser 原型 (prototype)。
struct parser
{
template<typename ParserState_t>
static bool Match(ParserState_t& p);
};
在 yardparser 裡面每一個 parser 都定義成一個 struct,struct 裡面定義一個回傳值型別是 bool 名稱叫作 Match 的 static 函數。這條 Match 函數就是 yardparser 的核心函數,用來作語法匹配,底下透過一個簡單的範例來看看它是如何使用。
struct Integer
{
template<typename ParserState_T>
static bool Match(ParserState_T& p) {
const char* p0 = p.GetPos();
if (c_grammer::DecNumber::Match(p)) {
string s(p0, p.GetPos());
int n = atoi(s.c_str());
return true;
}
return false;
}
};
如上面的簡單範例,Integer 定義了 Match 方法,在 Match 方法中透過 yardparser 內建的 c_grammer 中的 DecNumber 解析器來匹配數字。如果 DecNumber 的 Match 方法回傳成功,則表示目前匹配的字串是一個數字。不像是 Boost Spirit 的動作程式碼那麼直接,每一個動作程式碼函數的參數本身就已是轉換好的資料,可以直接使用,yardparser 的動作程式碼需要自行將這個數字由字串裡抽取出來,轉換成內部資料儲存以備後續使用。
如下所列 ,寫下算式計算機的 EBNF 表示式。
factor := integer | '(' expression ')'
term := factor (('*' factor) | ('/' factor))*
expression := term (('+' term) | ('-' term))*
首先將以上的 EBNF 表示式轉換為使用 yardparser 定義,不帶動作程式碼,如下。
struct Factor : Or<Integer, Seq<Char<'('>,
Expression, Char<')'> > > {};
struct Term : Seq<Factor, Star<Or<Seq<Char<'*'>, Factor>,
Seq<Char<'/'>, Factor> > > > {};
struct Expression : Seq<Factor, Star<Or<Seq<Char<'+'>,
Term>, Seq<Char<'-'>, Term> > > > {};
轉換後的 yardparser 程式定義如果沒有問題的話,應該能夠順利通過編譯,而且已經可以實際用來解析算式語法,只不過還沒加上動作程式碼所以還不能有真正的作用。
以下開始加上動作程式碼。如同前面的範例,需要加上動作程式碼的地方有五處,其中一個是將數字取出,以及加減乘除四種運算。取出數字的動作程式碼在上一節中已列出,底下說明如何加入加減乘除運算的動作程式碼。如下所示定義為加上動作程式碼後的語法程式定義。
struct Factor : Or<Integer, Seq<Char<'('>, Expression, Char<')'> > > {};
struct Term : Seq<Factor, Star<Or<DoMul<Seq<Char<'*'>, Factor> >,
DoDiv<Seq<Char<'/'>, Factor> > > > > {};
struct Expression : Seq<Term, Star<Or<DoAdd<Seq<Char<'+'>, Term> >,
DoSub<Seq<Char<'-'>, Term> > > > > {};
以上四個動作程式碼:DoMul、DoDiv、DoAdd 及 DoSub 分別為四種運算的動作程式碼。可以很明顯的看出來,加上動作程式碼後,沒辨法像使用 Boost Spirit 一樣一眼就能夠分辨出那一部份是語法,那一部份是動作程式碼。
最後加上一個用來作運算的數字堆疊,再整合 Integer 及四則運算的動作程式碼,完成算式計算機實作,其它部份程式碼如下所示。
vector<int> stack;
template<class RuleT>
struct DoMul
{
template<typename ParserState_T>
static bool Match(ParserState_T& p) {
if (RuleT::Match(p)) {
stack[stack.size() - 2] *= stack[stack.size() - 1];
stack.pop_back();
return true;
}
return false;
}
};
template<class RuleT>
struct DoDiv
{
template<typename ParserState_T>
static bool Match(ParserState_T& p) {
if (RuleT::Match(p)) {
stack[stack.size() - 2] /= stack[stack.size() - 1];
stack.pop_back();
return true;
}
return false;
}
};
template<class RuleT>
struct DoAdd
{
template<typename ParserState_T>
static bool Match(ParserState_T& p) {
if (RuleT::Match(p)) {
stack[stack.size() - 2] += stack[stack.size() - 1];
stack.pop_back();
return true;
}
return false;
}
};
template<class RuleT>
struct DoSub
{
template<typename ParserState_T>
static bool Match(ParserState_T& p) {
if (RuleT::Match(p)) {
stack[stack.size() - 2] -= stack[stack.size() - 1];
stack.pop_back();
return true;
}
return false;
}
};
int main(void)
{
std::string str;
while (getline(cin, str)) {
if (str.empty() || 'q' == str[0] || 'Q' == str[0]) {
break;
}
SimpleTextParser parser(str.c_str(), str.c_str() + str.length());
if (!parser.Parse<Seq<Expression, EndOfInput> >()) {
break;
}
cout << str << " = " << stack.back() << "\n";
stack.clear();
}
return 0;
}
注意到上述的實作裡,將字元 parser Char 改為 CharTok,目的是允許在字元間可以插入額外空白,CharTok 由 c_grammer 集合所提供。
到此為止,我們已使用了三種不同的方法實作出具有同樣功能的算式計算機。這三種方法各有它們的優缺點,在下表中我們由幾個角度來對它們作比較。
| 實作難度 | 編譯時間 | 程式碼 | 執行時間 | |
|---|---|---|---|---|
| 手作 | 難 | 快 | 小 | ? |
| lex/yacc | 易 | 快 | 中 | 快 |
| Boost Spirit | 易 | 極慢 | 大 | 慢 |
| yardparser | 易 | 快 | 中 | 快 |
以實作的難易度來看,純手工的解析器是最困難的,不只是在設計上有困難,真正的困難在於當有問題發生時,在除錯上會花費掉相當大的代價。即使只是一個很簡單的功能,如我們上面所實作的測試程式也都很可能出現許多難以發覺的 bug。而相對來說,使用如 lex/yacc、Boost Spirit 或 yardparser 這樣的解析器產生工具就容易的多了,只需要將語法分析出來轉換為 (E)BNF 表示式就可以很容易的讓工具幫我們產生可以解析語法的解析器程式而不會出什麼差錯,若有什麼差錯發生也只會是我們的規則有問題,而不是解析器本身的問題,這是和手作的解析器有很大的差別。
以工具自動產生解析器的方法,主要的缺點會落在於編譯時間上以及產生出來的程式碼大小。尤其是以 Boost Spirit 來實作解析器時,因為 Boost 是 C++ Template Library,所以當實作的解析器規則數量大到一個程度時,會發現到編譯時間呈跳躍的方式成長,而編譯出來的程式碼大小,和手作的解析器比較起來,也是大上不少。
上一個章節裡學習到如何使用工具實作文字剖析器 (parser),在本章中我們選擇了使用 Boost Spirit 及 yardparser 作為工具實作出 STGE 語言剖析器,來編譯 STGE 語言腳本 (script)輸出可以直接在 STGE 虛擬機器 (virtual machine) 執行的中介指令。使用 yardparser 的好處是,和 Boost Spirit 比較起來,在使用上具有同樣的優勢,也就是可以以 C++ 程式碼的形式直接把剖析器本身實作在專案程式裡,而不必像 lex/yacc 一樣需要另外提供外部腳本,再透過額外工具編譯成 C/C++ 程式碼再和專案程式一起編譯。同時和 Boost Spirit 相比較,最重要的好處理編譯時間大大的減少,以及獲得較好的執行速度。
在實作語言剖析器之前,第一步是先寫出語言的 EBNF 語法定義。
STGE 語言是由零個以上的 script 區塊所構成,如下所示以 EBFN 語法來表示。
top := script*
top 是一個 STGE 腳本程式的最上層進入點,它包含零個以上個 script 區塊。每一個 script 區塊是由關鍵字 script 及 end 所包圍的一個區塊所構成,緊跟著 script 關鍵字之後是代表這個區塊的一個名稱字串,而在 script 及 end 關鍵字中間包含了零個以上的 command 指令。
script := "script" IDENTIFIER command* "end"
根據我們的定義,在 STGE 裡面所使用的名稱字串只能使用英文字母大小寫字元以及數字再加上底線符號,同時規定名稱字串不能以數字作為開頭。以下是名稱字串 IDENTIFIER 的定義。
IDENTIFIER := (alpha | '_') (alnum | '_')* alpha := 'a' | 'b' | … | 'z' | 'A' | 'B' | … | 'Z' alnum := alpha | '0' | '1' | … | '9'
程式區塊的內容是由零個以上的指令所構成,STGE 語言共有14種指令,完整的 command 的定義如下。
command := repeat | option | fork | call | fire | sleep | direction |
speed | changedirection | changespeed | changex | changey |
clear | userdata
以上是 STGE 語言的基本結構的定義。
STGE 語言的算式除了再加上和 STGE 語言有關的一小部份擴充之外,其餘就和一般的算式一模一樣。這些擴充的部份就是前面在第三章裡提到的幾個基本函式功能以及變數的支援。
expression := term (('+' term) | ('-' term))*
term := factor (('*' factor) | ('/' factor))*
factor := real | ('(' expression ')') | ('-' factor) | ('+' factor) |
"$rep" | "$1" | "$2" | "$3" | "$4" | "$5" | "$6" | "$x" | "$y" |
"$w" | "$h" | "$dir" | "$speed" |
("sin" | "cos") '(' expression ')' |
"rand" '(' (expression (',' expression)?)? ')'
如上面所看到的定義 STGE 語言的算式和一般四則運算式不同的地方,主要是增加了和 STGE 引擎有關的幾種變數,以及三角函數 sin 及 cos,還有亂數函式 rand。
這個語法能夠支援巢狀的算式。因為我們的算式裡頭有提供幾個基本函式功能,而這幾個函式的參數也是個算式,因此套用這些規則能夠寫出很複雜的算式。如下展示的是一個還算複雜的例子。
rand(10, ($1 + rand(100 + $2 * sin($3), 400)) / 10, 20 + 5 * $rep)
repeat 指令的語法和 script 區塊很相似,這條指令的差別也只有關鍵字不同而已。
repeat := "repeat" '(' expression ')' command* "end"
option 指令的語法和 script 區塊也是很相似,這條指令的差別除了關鍵字不同之外,多了一個有有可無的 else 指令。
option := "option" '(' expression ')' command* ("else" command)? "end"
fire、fork 和 call 指令也是類似的指令,主要差別也是只有關鍵字不同。fire 指令比較特別一點,在參數上和 fork 和 call 指令有一些不同,其它部份語法也都是一樣。這個三個指令的參數列的個數可以是最少零個到最多六個。
fork := "fork" '(' IDENTIFIER paramlist ')'
call := "call "(' IDENTIFIER paramlist ')'
fire := "fire" '(' (IDENTIFIER paramlist)? ')'
paramlist := (',' expression (',' expression (',' expression (','
expression (',' expression (',' expression)?)?)?)?)?)?
sleep 指令就單純多了,它只有一個用來指定睡眠時間長度的參數,而這個參數可以是一個上面定義過的算式。
sleep := "sleep" '(' expression ')'
direction 和 speed 指令除了指令名稱和參數內容不同外,也可歸成一類。direction 和 speed 指令的第一個參數都是一個算式,第二個參數都可有可無。direction 指令的第二個參數是三種不同的參考值之一,而 speed 指令的第二個參數則是二選一。
direction := "direction" '(' expression (',' ("aim" | "add" | "obj")? ')'
speed := "speed" '(' expression (',' ("add" | "obj")? ')'
changedirection 和 changespeed 同樣歸類成一組。除了在前面多增加一個參數之後,後面接的參數列的定義和 direction 和 speed 指令的參數列定義相同。
changedirection := "changedirection" '(' expression ',' expression (
',' ("aim" | "add" | "obj")? ')'
changespeed := "changespeed" '(' expression ',' expression (
',' ("add" | "obj")? ')'
changex 和 changey 也是同樣一類的指令。同樣的,除了在前面多增加一個參數之後,後面接的參數列的定義和 direction 和 speed 指令的參數列定義相同。
changex := "changex" '(' expression ',' expression (',' ("add" | "obj")? ')'
changey := "changey" '(' expression ',' expression (',' ("add" | "obj")? ')'
clear 是最簡單的指令,不帶任何參數。
clear := "clear" '(' ')'
最後一個指令是 userdata。參數列的個數可以是最少一個到最多四個。
userdata := "userdata" '(' expression (',' expression (',' expression (','
expression)?)?)? ')'
STGE 語言的註解定義為只要是分號 (;)之後的字元都被當作註解忽略掉。
skip := space | ';' any*
上一節我們已經將 STGE 語言的語法以 BENF 語法定義出來了,接下來這節的工作就是把上述的 EBNF 語法使用 C++ 語言以 Boost Spirit 來實作。
Boost Spirit 有內建的一個空白字元解析器 space_p 用來過濾多餘的空白字元,我們只需要再加上對於註解的過濾就可以了。Boost Spirit 提供了一個方便的註解解析器 comment_p 給我們使用,我們只需要將註解字元或字串丟給它,讓這個註解解析器去幫我們過濾輸入的字元串流。整個定義很簡單,完整的定義如下。
struct Skip : public grammar<Skip>
{
template <typename ScannerT>
struct definition
{
rule<ScannerT> skip;
definition(Skip const& self)
{
skip
= space_p | comment_p(';')
;
}
rule<ScannerT> const& start() const { return skip; }
};
};
STGE 語言總共用使用了16個保留字,大部份都是指令名稱。我們使用 Boost Spirit 的 symbols 建立一個符號表,這樣子當解析器需要過濾名稱字串時也能快速作查找。
symbols<> keywords;
keywords = "script", "end", "repeat", "option", "fork", "call", "fire",
"sleep", "direction", "speed", "changedirection", "changespeed",
"changex", "changey", "clear", "userdata";
習慣上我們會將常使用到的常數獨立出來,這樣作除了方便統一管理外,也能避免在程式中重複撰寫同樣的字串時產生的手誤。除了常數字串之外,我們也將標點符號特別獨立出來,理由也是一樣。
rule<ScannerT> COMMA, LB, RB;
COMMA = chlit<>(',');
LB = chlit<>('(');
RB = chlit<>(')');
rule<ScannerT> SCRIPT, END, REPEAT, OPTION, ELSE, FORK, CALL, FIRE,
SLEEP, DIRECTION, SPEED, CHANGEDIRECTION, CHANGESPEED,
CHANGEX, CHANGEY,CLEAR, USERDATA;
SCRIPT = strlit<>("script");
END = strlit<>("end");
REPEAT = strlit<>("repeat");
OPTION = strlit<>("option");
ELSE = strlit<>("else");
FORK = strlit<>("fork");
CALL = strlit<>("call");
FIRE = strlit<>("fire");
SLEEP = strlit<>("sleep");
DIRECTION = strlit<>("direction");
SPEED = strlit<>("speed");
CHANGEDIRECTION = strlit<>("changedirection");
CHANGESPEED = strlit<>("changespeed");
CHANGEX = strlit<>("changex");
CHANGEY = strlit<>("changey");
CLEAR = strlit<>("clear");
USERDATA = strlit<>("userdata");
rule<ScannerT> AIM, ADD, OBJ;
AIM = strlit<>("aim");
ADD = strlit<>("add");
OBJ = strlit<>("obj");
注意到上面的定義中,STGE 的所有關鍵字全部都是英文小寫字母構成。
STGE 腳本文件是由 script 區塊所構成。在上面我們已經將文件的主體語法寫成了 EBNF 格式,轉換成 Boost Spirit 很容易。
rule<ScannerT> top, script; script = SCRIPT >> IDENTIFIER >> *command >> END ; top = *script >> end_p ;
IDENTIFIER 以 Boost Spirit 的語法來實作就更簡單了,這邊除了直接翻譯 EBNF 規則之外,額外還再增加過濾掉關鍵字的處理。
rule<ScannerT> IDENTIFIER;
IDENTIFIER
= lexeme_d[
((alpha_p | '_') >> *(alnum_p | '_'))
- (keywords >> anychar_p - (alnum_p | '_'))
]
;
command 規則就更簡單了,直接翻譯就行了。
rule<ScannerT> command, repeat, option;
rule<ScannerT> fork, call, fire, sleep, direction, speed,
changedirection, changespeed, changex, changey, clear,
userdata;
command
= repeat | option | fork | call | fire | sleep | direction | speed
| changedirection | changespeed | changex | changey | clear | userdata
;
寫到這裡,相信能夠愈來愈體會到 Boost Spirit 的威力。雖然我們還沒有真正使用 Boost Spirit 完成一個解析器來解析文件,但光只是能夠直接把 EBNF 語句翻譯成 C++ 程式碼,這件事情對我們來說就已經是件了不起的事情了。
算式的三條規則幾乎沒什麼需要改變,直接翻譯就行了。
rule<ScannerT> expression, term, factor;
expression
= term >> *(('+' >> term)
| ('-' >> term))
;
term
= factor >> *(('*' >> factor)
| ('/' >> factor))
;
factor
= real_p
| (LB >> expression >> RB)
| ('-' >> factor)
| ('+' >> factor)
| "$rep" | "$1" | "$2" | "$3" | "$4" | "$5" | "$6" | "$x" | "$y" |
"$w" | "$h" | "$dir" | "$speed"
| "sin" >> LB >> expression >> RB
| "cos" >> LB >> expression >> RB
| "rand" >> LB >> !(expression >> !(COMMA >> expression)) >> RB
;
factor 裡使用到的字面常數就沒有另外獨立出來。
程式指令基本上和算式一樣,直接翻譯即可。
rule<ScannerT> paramlist, usrparamlist, dirparamlist, spdparamlist;
rule<ScannerT> command, repeat, option;
rule<ScannerT> fork, call, fire, sleep, direction, speed,
changedirection, changespeed, changex, changey, clear,
userdata;
paramlist
= !(COMMA >> expression >> !(COMMA >> expression >>
!(COMMA >> expression >> !(COMMA >> expression >>
!(COMMA >> expression >> !(COMMA >> expression))))))
;
usrparamlist
= expression >> !(COMMA >> expression >>
!(COMMA >> expression >> !(COMMA >> expression)))
;
dirparamlist
= !(COMMA >> (AIM | ADD | OBJ))
;
spdparamlist
= !(COMMA >> (ADD | OBJ))
;
command
= repeat | option | fork | call | fire | sleep | direction |
speed | changedirection | changespeed | changex | changey |
clear | userdata
;
repeat
= REPEAT >> LB >> expression >> RB >> *command >> END
;
option
= OPTION >> LB >> expression >> RB >> *command !(ELSE command) >> END
;
fork
= FORK >> LB >> IDENTIFIER >> paramlist >> RB
;
call
= CALL >> LB >> IDENTIFIER >> paramlist >> RB
;
fire
= FIRE >> LB >> !(IDENTIFIER >> paramlist) >> RB
;
sleep
= SLEEP >> LB >> expression >> RB
;
direction
= DIRECTION >> LB >> expression >> dirparamlist >> RB
;
speed
= SPEED >> LB >> expression >> spdparamlist >> RB
;
changedirection
= CHANGEDIRECTION >> LB >> expression >> COMMA >>
expression >> dirparamlist >> RB
;
changespeed
= CHANGESPEED >> LB >> expression >> COMMA >> expression >>
spdparamlist >> RB
;
changex
= CHANGEX >> LB >> expression >> COMMA >> expression >>
spdparamlist >> RB
;
changey
= CHANGEY >> LB >> expression >> COMMA >> expression >>
spdparamlist >> RB
;
clear
= CLEAR >> LB >> RB
;
userdata
= USERDATA >> LB >> usrparamlist >> RB
;
到此為止我們已經把 STGE 語言的語法都轉換為 Boost Spirit 語法,以上的程式碼是已經可以編譯並執行來剖析 STGE 腳本文件。差別只在於它只能用於剖析 STGE 腳本文件但不能將剖析的結果作進一步利用,要作到這一步還需要插入動作程式碼才行。接下來我們會使用 yardparser 來實作 STGE 語言剖析器並實作動作程式碼,所以這部份的工作就留給讀者自行練習吧。
在本章中,我們要設計並實作出一個簡單的測試工具,可以用來載入 STGE 語言腳本 (script),並以視覺化的形式呈現執行結果。有了這個工具,在遊戲的開發過程中可以協助我們快速測試我們所編寫的 STGE 腳本。
這個測試工具使用網頁相關技術開發,結合 HTML (排版) + CSS (風格樣式) + Javascript (控制操作),利用 HTML5 的 Canvas 作畫面效果呈現 STGE 虛擬機器 (virtual machine) 的執行結果。而因為 STGE 語言的剖析器 (parser) 及虛擬機器 (virtual machine) 為使用 C++ 語言實作,為了可以讓同樣的程式碼也能夠在 Web 工具程式使用,所以透過 Emscripten 將 C++ 程式碼編譯為 Javascript 腳本,這樣就能夠整合進 Web 工具。
STGE 語言腳本的測試工具,主要的目的有兩個:
滿足這兩個核心需求,即可達成測試工具的目的。根據這兩個需求,設計如下圖所示的測試工具操作介面。
畫面白色方塊為一 HTML textarea 元件,可將 STGE 語言腳本 (script) 輸入此元件後,點擊 Parse 按鈕對輸入內容剖析 (parse)。若成功則左測方塊下方的下拉式選單 (drop-down menu) 列出所有可選擇的腳本 (script),否則顯示基本的錯誤提示訊息。
畫面黑色方塊為一 HTML5 Canvas,成功載入腳本 (script) 後,在其下方的下拉式選單選擇一個腳本 (script),並點選 Run 按鈕執行。STGE 虛擬機器 (virtual machine) 的執行結果,會顯示在此 Canvas 上。
HTML 是 Hyper Text Markup Language 的縮寫,是用來建立網頁的標記語言 (markup language)。透過文字標籤,可以用來描述定出一個樹狀 (tree) 的結構化的網頁文件。HTML 包含了許多不同種類的元件,可以讓網頁在瀏覽器 (browser) 顯示不同類型的媒體內容。
底下是一個簡單 HTML 文件範例內容。
<!DOCTYPE html> <html> <head> <title>標題</title> </head> <body> <h1>標題</h1> <p>段落</p> </body> </html>
<!DOCTYPE html> 開頭宣告這是一個 HTML5 的文件。<html> 標籤定義此文件的最上層元素 (element)。<head> 是用來描述此 HTML 文件的屬性,如 <title> 是用來指定此文件的標題,此標題會被顯示在瀏覽器的標題 (title bar) 上。<body> 標籤定義此文件的內容本體,也就是所有實際會顯示在瀏覽器上的內容,包含文字、圖片等。<h1> 是一個用來定義1號字體的標題的標籤,而 <p> 是用來定義一個文字段落的標籤。
所有的 HTML 標籤都是以如下格式定義:
<tagname>這是內容</tagname>
如上面範例裡面的 html、head、title、body、h1 及 p 等等,都是屬於一個 HTML 標籤。因為 HTML 是一文字文件,所以任何只要能夠編輯文字 (text) 檔的編輯器,都能夠用來編輯 HTML 文件,所以非常方便。
瀏覽器是用來顯示 HTML 網頁文件的工具,它並不會顯示 HTML 標籤。而是在瀏覽器載入 HTML 文件後,解析文件結構並以此決定如何顯示,最後呈現給使用者。
HTML 裡的 div 元素作為容器 (container),可以很好的用來描述文件的結構。測試工具的 HTML 排版 (layout) 使用兩個 div 容器,將上述工具介面裡的白色方塊和黑色方塊區隔。在各自的 div 容器裡面,再加入各自的輸入子元件。
如下所示,為黑色 Canvas 方塊的 HTML 排版。這個 div 容器裡面,首先放入的為一個 HTML5 Canvas 元素。接下來再放入一個 div 容器,再此容器裡再放入一個 select 及 button 元件。select 元件用來作為當成功載入腳本後的下拉式選單 (drop-down menu),用以列出所有可執行測試的腳本。而 button 元件,則用來觸發執行 select 元件選取的腳本名稱並顯示在 Canvas 元件上供使用者檢視執行結果。
<div>
<canvas>
</canvas>
<div>
<select><option>test</option>
</select>
<button>Run</button>
</div>
</div>
如下所示,為白色腳本輸入區方塊。在這個 div 容器裡只放入二個介面元素,第一個為輸入區 textarea,以及一個 button 元件用以觸發輸入腳本的剖析及轉換。
<div> <textarea></textarea> <button>Parse</button> </div>
以上的 HTML 排版在網頁瀏覽器 (browser) 上的顯示結果如下所示。
此結果和介面設計一節所預計的排版畫面效果差異很大,要達到預想的結果還需要加入 CSS 樣式控制才行。
CSS 是 Cascading Style Sheets 的縮寫,是用來改變網頁的包含顏色排版等等的樣式風格 (style) 的語言。使用 CSS,可以定義網頁裡的元素 (element) 如何在瀏覽器上顯示。甚至也能定義在印表機列印時的樣式,或其它媒體上的顯示樣式等等。透過把和顯示相關的樣式 CSS 從網頁 HTML 裡抽離,讓 HTML 專注在文件格式,並使用 Javascript 控制邏輯互動。以這種方式作網頁開發,對開發人員來說可以把工作作更好的分工,也提高可維護性。同時也能很便利的改變整個網站的風格,而不必作太大改動。
如下所示為一 CSS 範例。
body {
background-color: lightblue;
}
h1 {
color: white;
text-align: center;
}
每一條 CSS 規則包含一個選擇器 (selector) 及宣告 (declaration) 區塊。選擇器指向一個 HTML 標籤或使用者自訂的類別或 ID,而宣告區塊可以包含一個以上的以分號 (;) 分隔開的宣告。每一個宣告為一對屬性 (property) 及值 (value)。如上例的 body 的 CSS 規則宣告裡,指定 background-color (背景顏色) 為 lightblue (淺藍色)。
CSS 有三種不同的使用方式。
如下所示為一使用外部 CSS 檔案的網頁範例,此 HTML 檔案引入一外部定義的 CSS 檔案 mystyle.css。
<!DOCTYPE html> <html> <head> <link rel="stylesheet" href="mystyle.css"> </head> <body> <h1>標題</h1> </body> </html>
mystyle.css 的內容如下。
body {
background-color: lightblue;
}
h1 {
color: red;
margin-left: 20px;
}
HTML 內部 CSS 定義方式如下。
<!DOCTYPE html>
<html>
<head>
<style>
body {
background-color: lightblue;
}
h1 {
color: red;
margin-left: 20px;
}
</style>
</head>
<body>
<h1>標題</h1>
</body>
</html>
以下是嵌入式行內 CSS 的範例。
<!DOCTYPE html> <html> <body style="background-color:lightblue;"> <h1 style="color:red;margin-left:20px;">標題</h1> </body> </html>
以上三個範例最後得到的顯示結果完全一樣。視實際應用,三種不同使用方式也能混合使用。
首先替 canvas 及 textarea 加上寛 (width) 及高 (height) 的樣式。如下所示,以直接將樣式內嵌入 HTML 的方式。
<div>
<canvas width=400 height=400></canvas>
<div>
<select>
<option>test</option>
</select>
<button>Run</button>
</div>
</div>
<div style="width:400px;">
<textarea style="width:100%;height:400px;"></textarea>
<button>Parse</button>
</div>
顯示結果如下。
接著替 div 容器加入 float:left 屬性,讓它們在畫面寛度足夠的情況下可以並排顯示。因為替兩個 div 容器加上了 float:left 屬性,所以在最底下再補上一個作為清除 float 屬性的空的 span 元素,讓底下的排版顯示能回復預設值。
<div style="float:left;">
<canvas width=400 height=400></canvas>
<div>
<select>
<option>test</option>
</select>
<button>Run</button>
</div>
</div>
<div style="float:left;width:400px;">
<textarea style="width:100%;height:400px;"></textarea>
<button>Parse</button>
</div>
<span style="clear:both;display:table;"></span>
顯示結果如下。
最後再補上元素間的空白以及背景顏色樣式
<div style="float:left;margin-right:8px;width:400px;">
<canvas width=400 height=400 style="background-color:black;"></canvas>
<div>
<select>
<option>test</option>
</select>
<button>Run</button>
</div>
</div>
<div style="float:left;width:400px;">
<textarea style="width:100%;height:400px;"></textarea>
<button>Parse</button>
</div>
<span style="clear:both;display:table;"></span>
顯示結果如下。
以上,就完成了介面設計的排版。
Javascript 是世界上最受歡迎的三種程式語言之一,也是用來打造網站 (web) 的主要語言之一。Javascript 和 Java 語言雖然名字裡面都用 Java,但其實兩者是完全不同的程式語言。Javascript 是在1995年由 Brendan Eich 發明,而在1997年成為 ECMA 標準,官方標準的名稱為 ECMAScript。主流的瀏覽器都支援 Javascript 語言使用於前端 (frontend) 上,此外 Javascript 也能透過 Node.js 使用在後端 (backend) 服務器 (server)。
用來打造網站網頁的三種主要語言中,其中 HTML 是用來定義網頁的內容 (content),而 CSS 是用來定義網頁的排版 (layout) 及顯示樣式 (style),而 Javascript 則來用定義網頁的行為。透過使用 Javascript,可以用來操作 HTML DOM 動態改變 HTML 的內容及屬性值 (attribute),也能用來動態改變 HTML 的樣式 (CSS)。DOM 是Document Object Model 的縮寫。當一個 HTML 網頁被瀏覽器載入後,瀏覽器會建立這個網頁的元素物件 (object) 的樹狀 (tree) 結構。
getElementById 是一個常用的 API (application programming interface)。透過這個 API 可以取得在 HTML 內容中以指定 ID 命名的物件,得到和這個 ID 關聯的物件之後,就可以對它作變更操作。如下所示的 HTML 片段中,有一個 ID 為 test 的 img 元素。下面我們可以透過 getElementById 取得 test 物件,並對它作動態改變。
<img id="test" src="a.png" alt=""> </img>
以下 Javascript 程式範例,經由 test 物件的 innerHTML 屬性,動態改變它的內容。
document.getElementById("test").innerHTML = "Hello JavaScript";
注意到在 Javascript 範例中,字串可以使用單引號也能以雙引號括起來。因此以下範例和上一個範例得到的結果是一樣的。
document.getElementById('test').innerHTML = 'Hello JavaScript';
以下 Javascript 程式範例,改變 test 物件的 src 屬性值作到動態改變 img 元素指定的圖片檔名路徑。
document.getElementById('test').src = 'b.png';
以下 Javascript 程式範例,改變 test 物件的 style.width 即可動態改變物件寬度 (width),此效果和以 CSS 設定元素 width 樣式的結果相同。
document.getElementById('test').style.width = '100px';
以下 Javascript 程式範例,透過變更 test 物件的 style.display 屬性,即可動態隱藏或顯示物件。如下所示將物件的 style.display 設定為 'none',即動態隱藏物件。
document.getElementById('test').style.display = 'none';
以下將物件的 style.display 設定為 'block',即動態顯示物件。
document.getElementById('test').style.display = 'block';
以上的效果和透過 CSS 設定元素的 display 樣式的效果是相同的。
根據測試工具的介面設計:
也就是說所有的動作都是經由點擊介面上的按鈕後觸發的,因此底下陸續替兩個按鈕加上控制操作程式碼。HTML 裡的按鈕都是由 button 標籤所定義,如下所示定義一個顯示名稱為 hello 的按鈕,點擊 hello 鈕不作任何事情。
<button>hello</button>
現在替這個 hello 鈕加上簡單的控制操作程式碼,點擊時顯示一個彈出式對話盒,對話盒的內容顯示 hello 文字。
<button onclick="alert('hello')">hello</button>
如上面的範例所示,hello 鈕的啟始標籤裡新增了一個 onclick 屬性,內容為 "alert('hello')"。這一行程式會執行 alert 這個函式 (function),執行時代入參數字串 'hello'。alert 是 Javascript 內建的用來顯示彈出式對話盒的函式,代入的字串參數則會顯示在彈出式對話盒內。因此整個結果為:點擊 hello 鈕時,彈出一個對話盒,內容顯示 hello 字串,以及一個點擊時會關閉這個彈出式對話盒的確定鈕。
用同樣的方法替 Parse 鈕和 Run 鈕加上控制操作程式碼,同時也替 canvas、select 及 textarea 這三個元素分別加上 id 屬性,如下。
<div style="float:left;margin-right:8px;width:400px;">
<canvas id="canvas" width=400 height=400 style="background-color:black;"></canvas>
<div>
<select id="scripts">
</select>
<button onclick="run()">Run</button>
</div>
</div>
<div style="float:left;width:400px;">
<textarea id="code" style="width:100%;height:400px;"></textarea>
<button onclick="parse()">Parse</button>
</div>
<span style="clear:both;display:table;"></span>
run 及 parse 是我們接下來要實作的自定義函式,而剛才加入的 id 屬性是我們之後在程式裡面用來查找到指定介面元素的標記。
如下,先來看較簡單的 run 函式的實作。
function run() {
var scripts = document.getElementById('scripts');
var script = scripts.value;
stge.run(script);
}
函式的定義由 function 這個關鍵字開始,接著是至少一個空白字元,然後再接著是函式名稱。函式名稱由英文數字和符號構成的自定義字串組成,第一個字元不能是數字。函式名稱之後是一對小括號,括號內為這個函式宣告可接受的參數,最後整個函式的內容由一對大括號包括起來。此例中我們的函式名稱為 run,是一個沒有任何參數的函式。
run 定義的函式內容只有三行程式碼,每一行程式碼都以分號 (;) 結尾作區隔。第一行宣告一個變數名稱為 scripts,變數名稱定義的規則同函式名稱。變數的作用是把它為作一個具名的物件來指向某塊資料,宣告後就可以再之後的程式碼中以這個名稱存取同一塊資料。此例中宣告的變數 scripts 所表示的是在網頁中 id 為 'scripts' 的元素,也就是前面 HTML 裡的 select 元素,透過 document 這個代表目前網頁的物件的函式 getElementById 取得。
第二行再宣告一個 script 變數,儲存 scripts 物件裡的叫作 value 的變數的值,即 select 元素所選取的項目內容值,也就是使用者選取的想要執行的 STGE 腳本的名稱。最後一行呼叫 stge 物作,也就是 STGE 模組的 run 函式,傳入儲存在 script 變數裡的 STGE 腳本名稱。
注意到我們原本定義的 Run 鈕的 onclick 事件發生時呼叫的函式叫作 run,而在 run 內又呼叫了 stge 的 run。兩個函式名稱都叫作 run,其中和 Run鈕關聯的是屬於 global範圍 (scope) 的 run,而在 Run 鈕的 run 函式裡面呼叫的是屬於 stge 模組的 run。
因為 parse 函式比較複雜所以分為兩部份,第一部份是解析使用者輸入的程式碼,第二部份為將解析成功後的 script 名稱列表更新至 select 元素,讓使用者可以從中選擇要執行的 script。如下所示為 parse 函式的實作。
function parse() {
var code = document.getElementById('code').value;
if (stge.parse(code)) {
var names = stge.getScripts();
setScriptNames(names);
}
}
第一行程式碼宣告了一個名稱為 code 的變數,變數內容為 id 為 'code' 的 textarea 的文字內容。取出使用者輸入的程式碼文字內容後,透過 STGE 模組的 parse 函式解析程式碼,也就是把 code 變數傳遞給 STGE 模組的 parse 函式執行。如果解析成功則 STGE 模組的 parse 函式回傳 true,底下接著透過 setScriptNames 函式更新 select 列表內容。否則若 STGE 模組的 parse 函式回傳 false,則不作任何事。呼叫 setScriptNames 函式之前,首先宣告一個 names 變數,透過 STGE 模組的 getScripts 函式取出所有合法的 script 名稱列表。並把 names 作為參數傳遞給 setScriptNames 函式執行,讓 setScriptNames 函式將 names 的內容更新至 select 元素。
底下是 setScriptNames 函式的實作。
function setScriptNames(names) {
var scripts = document.getElementById('scripts');
scripts.innerHTML = '';
for (var i = 0; i < names.length; i++) {
var c = document.createElement('option');
c.text = names[i];
scripts.options.add(c);
}
}
首先宣告一個 scripts 變數用來呈接 document 裡 id 為 'scripts' 的元素,也就是 select 元素。接著透過 scripts 變數的 innerHTML 屬性將內容清空,這個動作會清空 select 元素的原有內容。接著透過一個迴圈遍例 names 變數裡的名稱列表,為每一個名稱新建一個 option 元素並加入 select 元素裡面。
Emscripten 是一組工具鏈 (toolchain),可用以將 C/C++ 原始程式碼 (source code) 透過 LLVM 相關技術編譯成 Javascript 腳本或 WebAssembly 指令,而 LLVM 則是一組編譯器 (compiler) 相關的工具鏈技術。
一般編譯器 (compiler) 設計如下圖所示主要分為三大功能模組:前端 (frontend)、最佳化器 (optimizer) 及後端 (backend)。前端如 C 編譯器將原始程式碼編譯成內部資料結構,經過最佳化 (optimize) 處理後,再生成目的機器相關的機器指令 (machine code)。

而 LLVM 將這三大塊模組抽離獨立出來,這樣只需更換不同前端即可支援編譯不同程式語言,過程產生的中間碼則可使用統一的最佳化方法作最佳化,最後更換不同後端即可支援生成不同目的機器的機器指令。
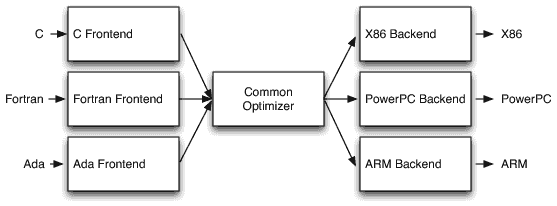
Emscripten 就是使用了 C/C++ 前端,即 LLVM clang 模組,將 C/C++ 原始程式碼編譯成中間碼 LLVM IR 再最佳化後,提供一後端輸出成 Javascript 腳本或是 WebAssembly 指令。
從官方網站下載及安裝好 Emscripten SDK 之後,便能夠在命令模式下透過 emcc (Emscripten Compiler Frontend) 來使用,emcc 會呼叫其它需要的工具來編譯你的原始程式碼。
底下寫了一個簡單的 hello_world.c 作為測試。
#include <stdio.h>
int main() {
printf("hello, world!\n");
return 0;
}
以任何文字編輯器編輯好程式並存檔後,在命令列模式下輸入如下指令。
$./emcc hello_world.c
如果沒有任何編譯錯誤發生的話,則可以看到一個預設名為 a.out.js 的輸出檔案。否則則可以在畫面上得到輸出的編譯錯誤訊息,著手修正錯誤存檔再重新以上步驟,直到成功通過編譯產生 a.out.js 為止。成功編譯輸出的 a.out.js 可以透過 Node.js 執行測試,查看執行結果。如果一切正確,則可在畫面上看到如預期的輸出 "hello, world!"。
$node a.out.js
任何一個程式中或多或少都有各式各樣的流程分支 (branch)。比較簡單的程式只有直線流程,從頭跑到尾就結束。有些程式就很複雜了,從程式一開始執行起,就不斷的在大大小小的流程分支內跑來跑去,不停的切換不同狀態 (state),以表示處於不同流程當中,且依據不同的流程以不同的子程序 (sub-routinue) 處理。在實作上,以往最簡單的作法就是加個狀態變數,用來表示不同的流程狀態。在程式主要控制流程的地方,以 if-else 或 switch 等方法來檢查這個變數是什麼內容,再決定呼叫對應的程式區塊或是子程序來處理。
本章要介紹狀態堆疊,是程式流程狀態機控制及管理的技術。透過狀態堆疊的技術讓我們根據程式的狀態以簡單直覺的方式來設計實作程式,大大的提高生產力和可維護性。本章以這樣的概念,設計實作了一個通用的資料結構:Stage Stack,專門用於輔助遊戲程式管理各個遊戲流程狀態。
仔細分析後,不管程式有多麼的複雜,程式中有多少種不同的狀態,在大部份的情形下同一時間只會有一個狀態是處於作用中 (active)。根據這個觀察,在不同的程式狀態之間的切換,存在和堆疊 (stack) 結構有很大的相似性,也就是說在同一時間中就只會有一個作用中的狀態,流程的變化相似於堆疊頂端操作。
考慮到這樣的相似性,我們可以將程式的流程類比成一個堆疊,提供如堆疊一樣的操作來作流程的控制切換。例如在遊戲進行中 (game playing state),當玩家按下了ESC鍵叫出遊戲選單 (game menu state),玩家執行其中一個選單功能或者再按一次 ESC 鍵的動作都會關閉選單,在選單關閉前遊戲是暫停狀態。這個狀況以堆疊的角度來看,相當於一開始推入 (push) 遊戲狀態至堆疊中,再推入選單狀態至堆疊中,然後彈出 (pop) 選單狀態,最後又回到遊戲進行中狀態 (堆疊頂端的狀態)。將遊戲程式邏輯狀態切換類比成堆疊操作,有助於我們對遊戲整體流程控制的思考,讓程式的設計更結構化。
堆疊主要的操作分別是堆入 (push) 及彈出 (pop),依據我們的需求要堆入及彈出的堆疊元素 (element) 為程式流程狀態。在設計上如果只是使用堆疊來管理程式流程狀態的話,那這個模組在使用上和直接用個狀態變數來管理程式流程狀態就不會有太大的差別。因此,我們要設計的堆疊不只要能夠管理程式流程狀態,就連處理對應的流程狀態的處理程序也要一起管理。這樣一來,這個堆疊在實際應用上會更有價值。
為了要讓堆疊也能夠管理流程狀態的處理程序,最理想的方式就是使用函式指標 (function pointer) 來作為堆疊元素。因此如果能夠讓流程狀態的處理程序變成是類別的成員函式 (member function) 的話,那麼在使用上及管理上一定能獲得更大的好處。所以每個流程狀態以一個對應的流程狀態處理程序,不同的狀態切換等於是在切換不同的狀態處理程序。因為這些狀態處理程序是堆放於堆疊內,每次在應用程式的主迴圈內定時的去執行當前狀態的處理程序時,只需執行在堆疊頂端的處理程序即可。
如上圖所示是一個簡單的遊戲類別,其中有四個遊戲狀態,分別是:Title (標題)、MainMenu (主選單)、Game (遊戲中) 及 Clear (過關)。遊戲一開始時為標題狀態 push 進 StageTitle,接著進入主選單狀態 push 進 StageMainMenu,選擇是否進行遊戲或者退出遊戲。若選擇進入遊戲則進入遊戲則 push 進 StageGame 狀態開始遊戲否則程式結束,或者玩家也能選擇再退回標題狀態。在 StageGame 狀態中進行遊戲若達成目標過關,則 pop 掉 StageGame 狀態並 push 進 StageGameClear 狀態演出過關畫面。最後再 pop 掉 StageGameClear 狀態回到主選單狀態重新選擇是否進行新遊戲或退出遊戲。
對於每一個狀態流程我們可以再附加一個子狀態,分別對應到當這個狀態流程推入堆疊、彈出堆疊或持續更新時的更新子狀態。除此之外還有二個額外的子狀態分別是:當一個狀態流程推入堆疊造成當前狀態流程暫停,以及當前堆疊頂端的狀態流程彈出堆疊造成上一個暫停的狀態流程繼續動作。加上子狀態後,對於程式的流程控制會更加簡便。子狀態會作為以狀態處理程序的一個參數傳遞給應用程式知道。子狀態所代表的意義如下:
class Game
{
StageStack<Game> m_stage; // 遊戲狀態堆疊.
};
上面這個簡單的類別 Game 為一個小遊戲的主體,其中宣告了一個名稱為 m_stage 的成員變數,型別為狀態堆疊類別 StageStack<Game>,這是一個 template 類別有一個參數傳入 Game。透過 m_stage 就能用來控制 Game 的遊戲流程,如 push 或 pop 等切換不同遊戲狀態。
這裡有個問題,為什麼不讓 Game 繼承 StageStack<Game> 呢?其實用繼承的方式在使用上也是合法的,只不過一般來說習慣都是以把狀態堆疊宣告為一個成員變數的方式來使用。因為使用這種方式就能夠在同一個類別中宣告多個狀態堆疊用於控制不同流程,但最終實際的實作可以視狀況而定。
在上一小節裡定義的小遊戲類別 Game 裡宣告的 m_stage 成員變數是用來操控遊戲的狀態堆疊,而遊戲中不同的狀態是以類別 Game 的成員函式來定義。
class Game
{
void stageTitle(int state, uint_ptr userData);
};
如上面例子所示定義了小遊戲類別 Game 的標題狀態處理函式原型。每一個狀態處理函式有二個參數,第一個參數 state 為前面介紹過的子狀態,每次狀態處理函式被呼叫時透過這個參數就能夠知道此函式是在什麼樣的情況被呼叫的。
void Game::stageTitle(int state, uint_ptr userData)
{
if (JOIN == state) {
// push 進堆疊時呼叫:作需要的初始化。
} else if (TRIGGER == state) {
// 每次 update 時呼叫:作周期處理。
} else if (LEAVE == state) {
// pop 出堆疊時呼叫:作需要的釋放動作。
} else if (SUSPEND == state) {
// 當有其它狀態 push 進堆疊疊在此狀態上時呼叫:處理暫停動作。
} else if (RESUME == state) {
// 當其它狀態 pop 出堆疊造成此狀態又重新動作時呼叫:處理必要的回復動作。
}
}
如上面例子所示,在狀態處理函式中根據不同的子狀態作不同的處理。至於狀態處理函式的第二個參數 userData 後面介紹狀態堆疊的定期更新時會再詳細說明。
開始使用狀態堆疊物件 m_stage 之前需先作一個初始化的動作,如下所示。
void Game::init()
{
m_stage.initialize(this, &Game::stageTitle);
}
StageStack::initialize 的第一個參數用來初始化這個狀態堆疊物件的父物件指標,在此例中為小遊戲類別 Game 的 this 指標。第二個參數指定一個初始的堆疊狀態的狀態處理函式指標,此例中為遊戲標題狀態 Game::stageTitle。狀態堆疊物件初始化後就能夠以堆入 (push) 及彈出 (pop) 方法來變更堆疊狀態。
void Game::stageMainMenu(int state, uint_ptr userData)
{
if (JOIN == state) {
createGameMainMenu();
} else if (TRIGGER == state) {
if (inputSelBackKey()) {
m_stage.pop(); // 返回 Game::stageTitle.
} else if (inputSelGame()) {
m_stage.push(&Game::stageGame); // 進入遊戲狀態,此會造成 stageMainMenu 變為暫停狀態.
} else if (inputSelExitGame()) {
exitGame();
}
} else if (LEAVE == state) {
destroyGameMainMenu();
} else if (SUSPEND == state) {
pauseGameMainMenu();
} else if (RESUME == state) {
resumeGameMainMenu();
}
}
上面的範例是小遊戲主選單的狀態處理函式,在狀態切換為主選單狀態時作了初始化動作將遊戲主選單建立起來,而在狀態切換為其它狀態時只作暫停動作,直到整個狀態真正從堆疊彈出時才作釋放動作將剛才建立的遊戲主選單所佔用的資源釋放掉。每次更新的時候根據玩家所作的輸入作不同的狀態切換,當玩家選擇退回鍵時則切換回標題狀態,選擇進行遊戲時則切換至遊戲狀態,選擇退出遊戲時則程式結束。
從主選單狀態切換回標題畫面時只需作一個 pop 動作,因為從標題狀態切換至主選單狀態時是作了一個 push 的動作將主選單狀態推入堆疊,所以退回時只需將主選單狀態彈出即可回到標題狀態。同樣的從主選單狀態切換至遊戲狀態也是將遊戲狀態推入堆疊,之後當要從遊戲狀態退回到主選單狀態時只需將遊戲狀態從堆疊彈出即能回到主選單狀態。
在下面的例子中 Game::update 是我們的小遊戲的周期更新函式,其中每次作更新時會對 m_stage 透過呼叫 StageStack::trigger 更新遊戲狀態,讓堆疊狀態物件對當前的狀態作更新。
void Game::update()
{
// ... 其它更新.
m_stage.trigger();
}
在對堆疊狀態物件作周期更新時所呼叫的 StageStack::trigger 函式沒有傳入任何參數,每一次呼叫都會轉呼叫到狀態堆疊頂端的當前狀態的狀態堆疊處理函式,以 TRIGGER 子狀態作為 state 參數及 userData 參數設為0。StageStack::trigger 函式也能夠接受一個參數,假如在呼叫 StageStack::trigger 時傳入一個指定參數,那麼最後轉呼叫到狀態堆疊頂端的當前狀態的狀態堆疊處理函式時,userData 參數就會原封不動的傳遞這個指定參數的值,同時 state 參數一樣以 TRIGGER 子狀態代入。
void NetGame::update()
{
// ... 其它更新.
m_netStage.trigger();
}
void NetGame::onNetMsgReady(NetMsg *pMsg)
{
// ... 其它處理.
if (pMsg) {
m_netStage.trigger(pMsg);
}
}
void NetGame::stageNetConnected(int state, uint_ptr userData)
{
if (TRIGGER == state) {
if (NULL != userData) {
// userData 不是 NULL 表示是從 onNetMsgReady 裡面 trigger 進來.
// 根據 pMsg (userData) 內容處理網路訊息.
} else {
// userData 是 NULL 表示是一般的 trigger.
// 根據網路流程狀態作對應周期更新處理.
}
}
}
上面的範例中 NetGame 是一個網路連線的小遊戲類別,m_netStage 是一個用來作為網路流程狀態控制及處理網路訊息的狀態堆疊物件。每次遊戲作周期更新或每次收到一個網路訊息時都會呼叫 m_netStage 的 trigger,差別是周期更新時呼叫 trigger 不代入參數而收到網路訊息時的呼叫將網路訊息當作 trigger 的參數代入呼叫。如果 userData 參數是 NULL 則表示此呼叫是由周期更新觸發,此狀況就只作跟網路流程相關的狀態更新切換等周期性處理。否則則是因為接收到一網路訊息而觸發,此狀況則根據透過 userData 參數遞而來接收到的網路訊息物件內容作對應處理。
底下是根據前面章節所討論所作的 Stage Stack 的 C++ 定義。
template<class T, int MAX_STAGE = 8>
class StageStack
{
T* m_pHost; // 指向堆疊物件的父物件.
int m_top; // 堆疊頂端索引.
Stage m_stack[MAX_STAGE]; // 狀態堆疊.
public:
typedef void (T::*Stage)(int state, uint_ptr param);
StageStack() : m_pHost(0), m_top(-1);
void setHost(T* pHost);
void initialize(T* pHost, Stage stage);
void push(Stage stage);
void pop(int popCount = 1);
void popAndPush(Stage stage, int popCount = 1);
void popAll();
void trigger(uint_ptr param = 0);
Stage top() const;
};
StageStack 類別是一個有二個參數的泛型類別,第一個參數為狀態堆疊物件擁有者的類別型別,第二個參數為狀態堆疊大小常數。m_stack 是一個用來作為堆疊儲存狀態處理函式指標的陣列,陣列的大小由類別參數 MAX_STAGE 決定。m_top 則指向堆疊頂端,所記錄的數值為一個指向 m_stack 的索引值。m_pHost 則是存放狀態堆疊物件擁有者的物件指標,因為 m_stack 中所存放的都是類別函式指標,當要呼叫這些指標所指函式時就會使用到 m_pHost 所存的類別物件指標。
除了前面己經介紹過的 initialize、push 及 pop 之外,這個類別還定義了幾個常用的函式。top 是用來取得目前狀態堆疊頂端的狀態處理函式指標。popAll 用來清除狀態堆疊內容,清除的方式是從堆疊頂端開始一個一個把全部的狀態全 pop 掉,所以每一個在堆疊內的狀態一樣都會被以 LEAVE 子狀態被呼叫一次。因為常常在作狀態切換時都是先作一個 pop 把常前狀態彈出,之後再把新狀態 push 進堆疊,這個函式把這二個動作合併成一個函式呼叫讓程式更簡便。除此之外 popAndPush 允許呼叫時傳入第二個參數,用來指定在作 push 之前要先 pop 掉幾個在堆疊上的舊狀態,方便切換流程應用。
在這一章裡,我們將會整合本書所有知識實作一個只有一個關卡 (level),但具體而微的縱向捲軸射擊遊戲 (STG)。先以在第八章建立的測試工具,編寫及測試遊戲所需要的 STGE 語言腳本 (script)。腳本的內容包含了關卡內容、敵機及頭目 (Boss) 的移動及攻擊、遊戲選單動態效果、遊戲背景星空以及爆炸特效等等。接著以 WTL (Window Template Library) 建立基本的遊戲主程式框架 (framework),並且加上 OpenGL (Open Graphics Library) 繪圖框架處理繪圖功能,聯結 STGE 虛擬機器 (virtual machine) 及語言剖析器 (parser),載入事先編輯好的腳本。遊戲中所有的物件都將會以 STGE 語言腳本產生及控制,我們所需要作的事情是,在我們的遊戲主程式裡,使用 OpenGL 對不同型別的物件作對應的繪製。這個射擊遊戲小品的主要目的在於示範如何應用 STGE 引擎及其相關技術來製作射擊遊戲,所以對於遊戲畫面的處理,我們只簡單的使用 OpenGL 繪製出基本圖形作表示,如點及三角形。至於聲音的處理則不在本書的討論範圍之內。